端口扫描,TCP端口
1 | PORT STATE SERVICE VERSION |
UDP端口
1 | PORT STATE SERVICE VERSION |
官网没有固件,打印机走的https流量,抓不到东西,打印机设置了http代理之后抓到了这么个流量

但是不是固件,只有几百字节,而且没有可见字符
个人猜测这是一个加密之后的存有固件下载链接的文件,打印机将其下载之后进行解密得到固件更新地址。
还是直接拆设备提固件吧,经过一顿折腾,拆下来了pcb板

flash上的丝印为winbond25Q128JVSQ,一款winbond公司的16MB大小的flash
热风枪吹下来用编程器进行提取,吹下来的时候不小心力气用大了一点把焊盘给拉起来了,不知道焊回去了还能不能用

可惜的是,从flash上提取下来的固件居然也是加密状态,只有极少数可见字符串
binwalk -E走一波
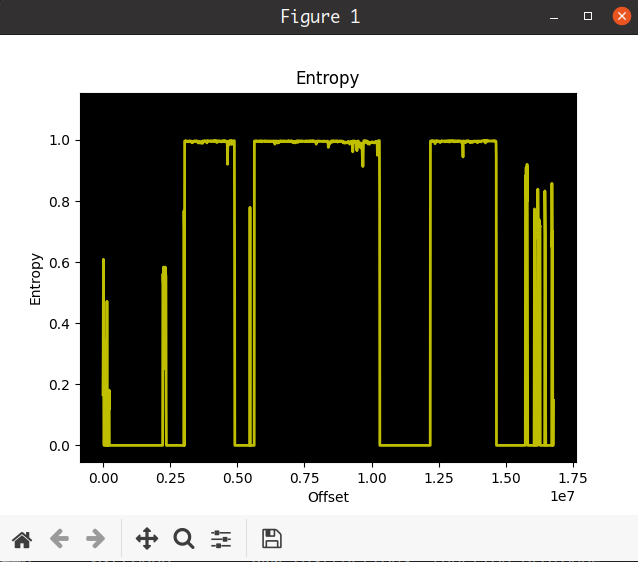
看那几道几乎水平的熵值,就知道这肯定有加密或这被压缩过了。
加密的固件必不可能运行,所以在被运行之前肯定有一个解密的过程。解密的过程通常由bootloader来完成,我们知道嵌入式系统在上电之后会先运行bootload初始化硬件并加载内核,所以bootloader肯定是不能处于加密状态的,bootloader都加密了那整个固件就没有一个可以运行的部分了。
对于有些设备,bootloader和固件是存在一个flash中的,而有些设备则是一个8M或者其他大小的flash用于存储flash,另一个NAND flash或者emmc用于存放固件。对于ts3480这款打印机而言只有一个16MB的flash,其bootloader和固件是存在一起的。
根据前面的分析,固件虽然处于加密状态,但肯定是有一小段未加密的数据的,这些数据我们要重点关注,其中应该会存在解密固件的关键。
binwalk -A 走一波,看看哪里能够识别成指令
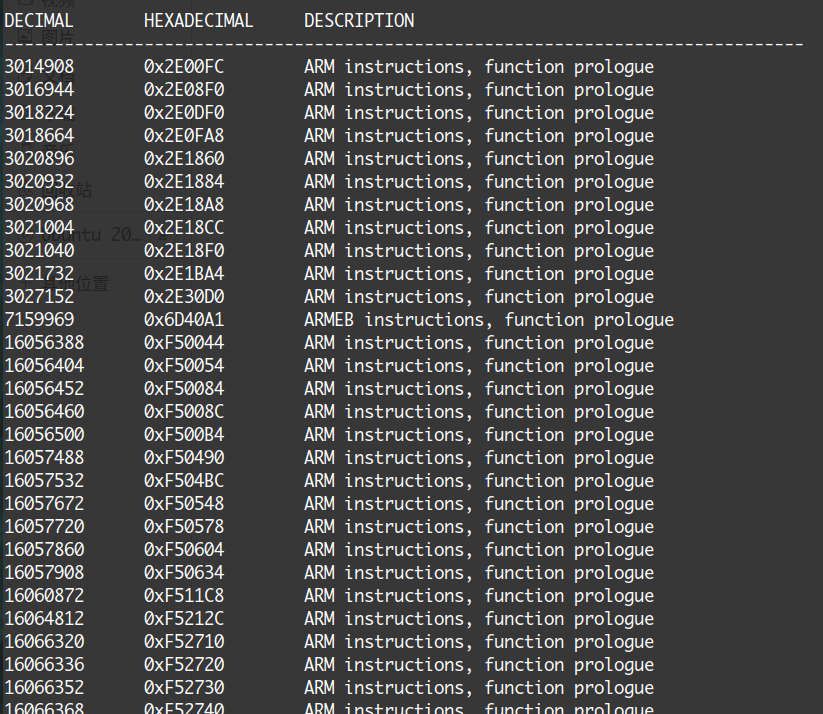
最开始的指令是0x2E00FC处,用010打开
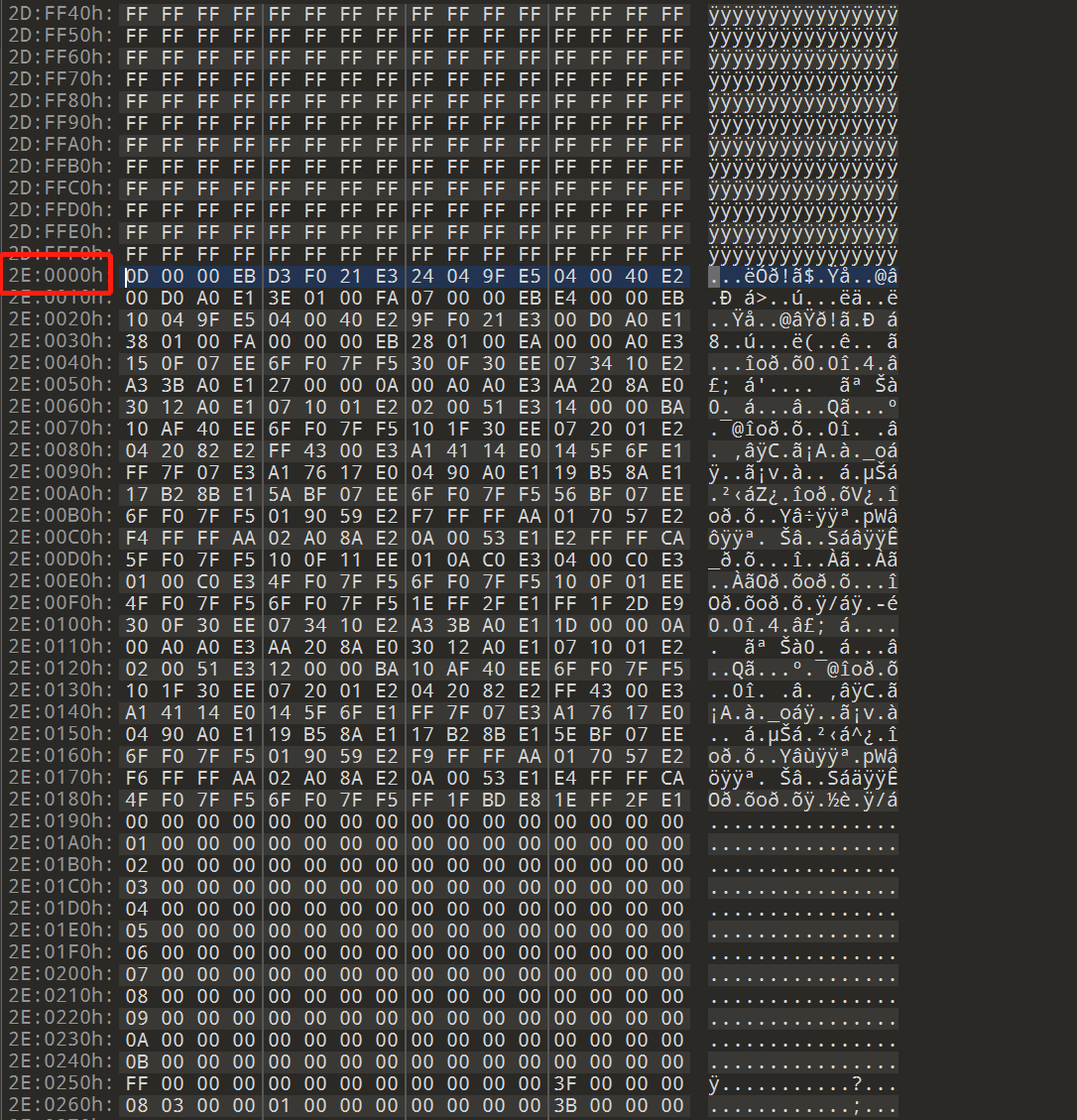
实际上,从0x2E0000开始才是有指令的位置,IDA打开并在0x2E0000处进行反编译
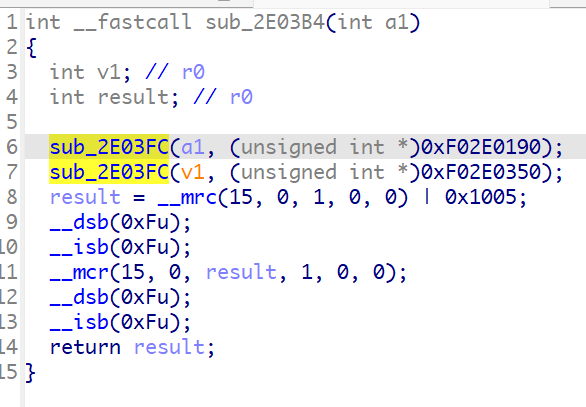
注意到0xF02E0190这个值,我们跳转到0x2E0190处看看
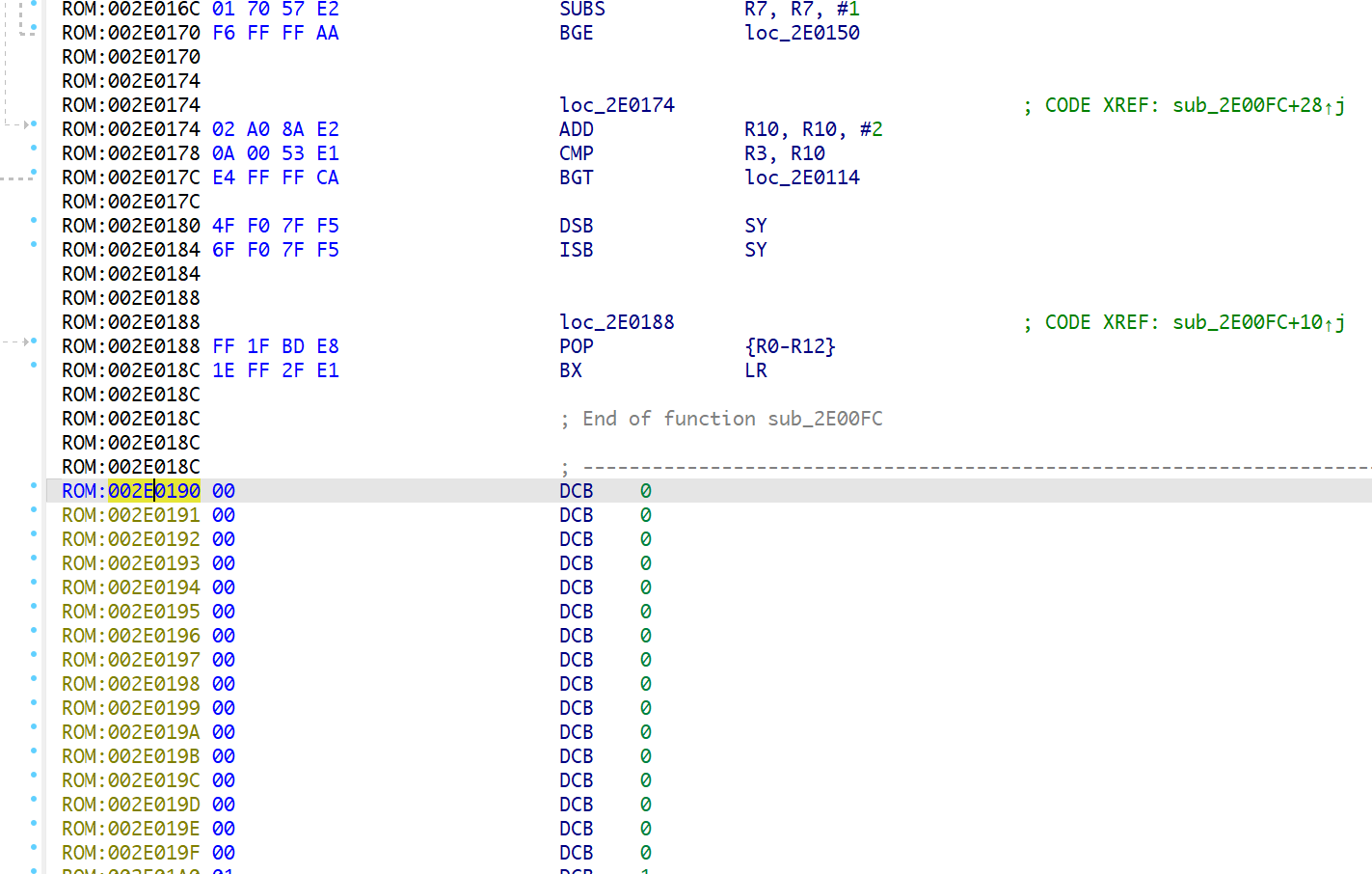
很巧,0x2E0190处正好是一段数据,所以猜测flash的加载地址为0xf0000000,重新设置flash的加载地址
继续往下看
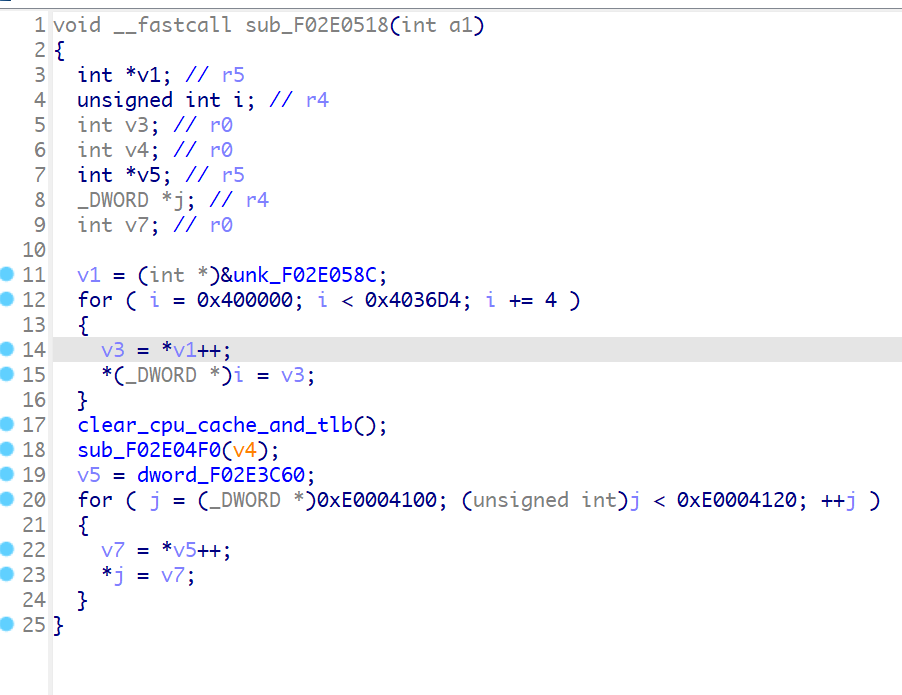
将从0xF02E058C开始的数据拷贝到0x400000处,拷贝长度为0x36d4
在这里可以使用如下命令
1 | dd if=ts3480.BIN of=first_ram_cpoy.bin bs=1 count=14036 skip=3016076 |
将0xF02E058C处的数据,也就是固件偏移为0x2E058C处、长度为0x36d4的数据提取出来
然后新建一个段
再使用IDA的附加二进制文件的功能
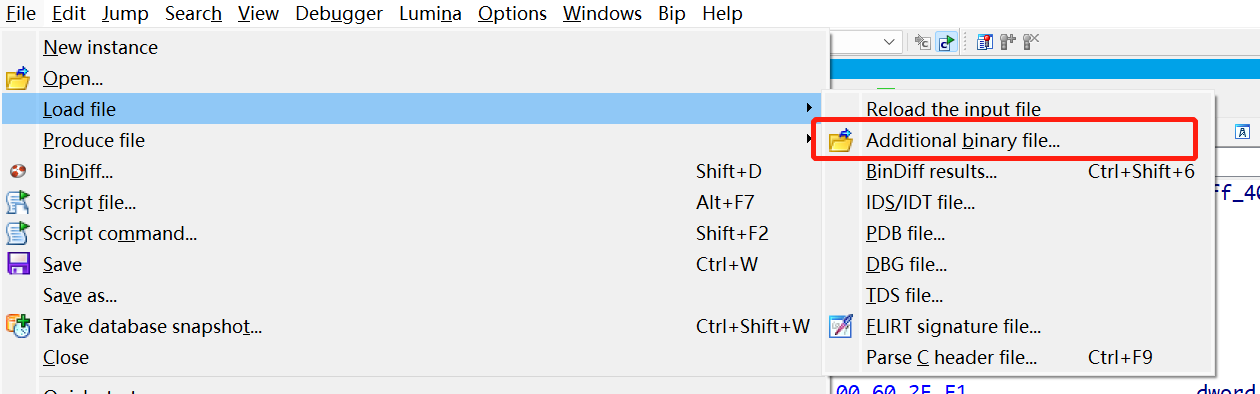
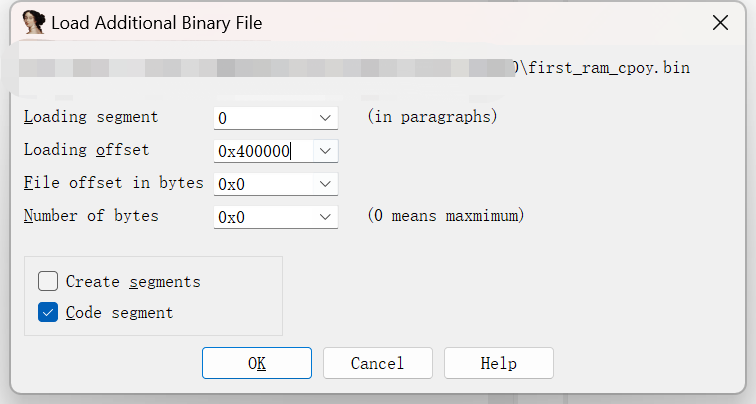
将这一段数据添加到我们刚刚创建好的段中,这样一来就模拟了前面的数据拷贝的操作。
再看到sub_F02E04F0函数,这个函数又会执行0x400312处的函数,而0x400000-0x4036d4处的数据已经被设置为了0xF02E058C处的数据
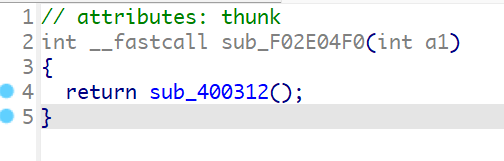
而sub_400312如下所示

跟进到sub_40017A函数中
很乱,不知所云,继续看到sub_402B44函数
根据函数内容恢复了两个可能的函数名,后续进入到一个类似于解压缩功能的函数

函数非常大,有一千多行,其中有一些关键的字符串帮助我们确定函数的功能是用来解压缩的,如下所示
后面的sub_4009A0函数意义不明,猜测用于解压缩后的收尾工作,回溯到上一层函数
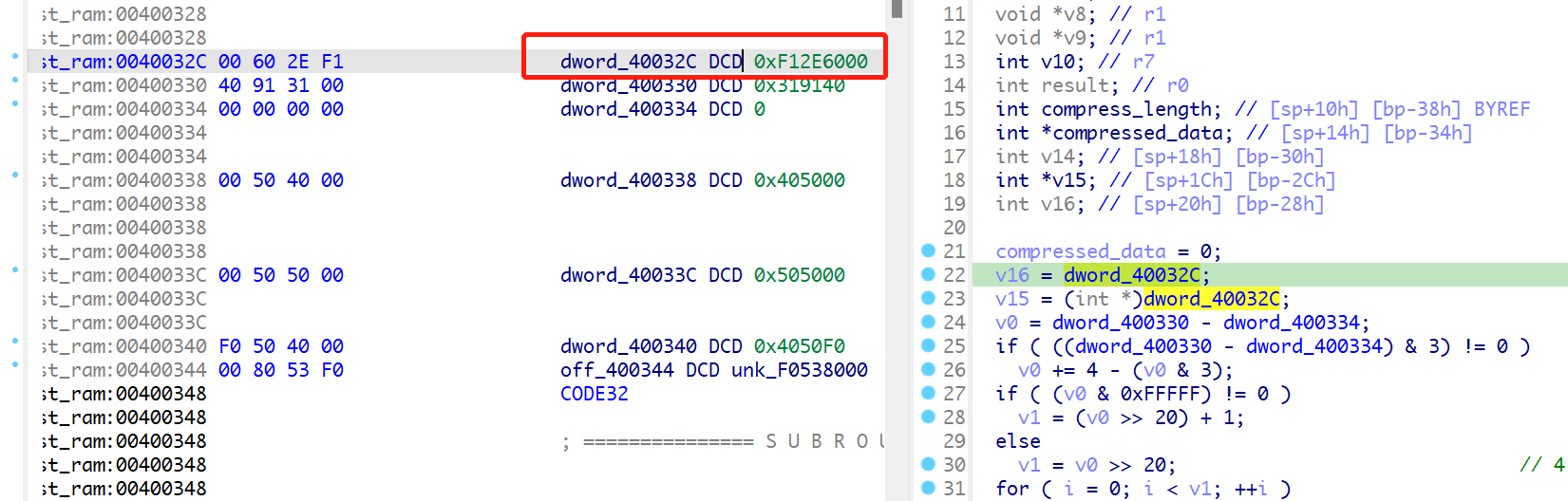
看到这,0xF12E6000并不在我们定义的地址范围内,flash的加载地址为0xF0000000,我们看到固件中偏移为0x2E6000处正好是一段数据的起始部分
猜测flash的数据并不止被映射到了0xf0000000-0xf1000000的地址范围,从0xf1000000-0xf2000000处同样被映射为了flash的数据
所以再创建一个段用于存放flash的副本。
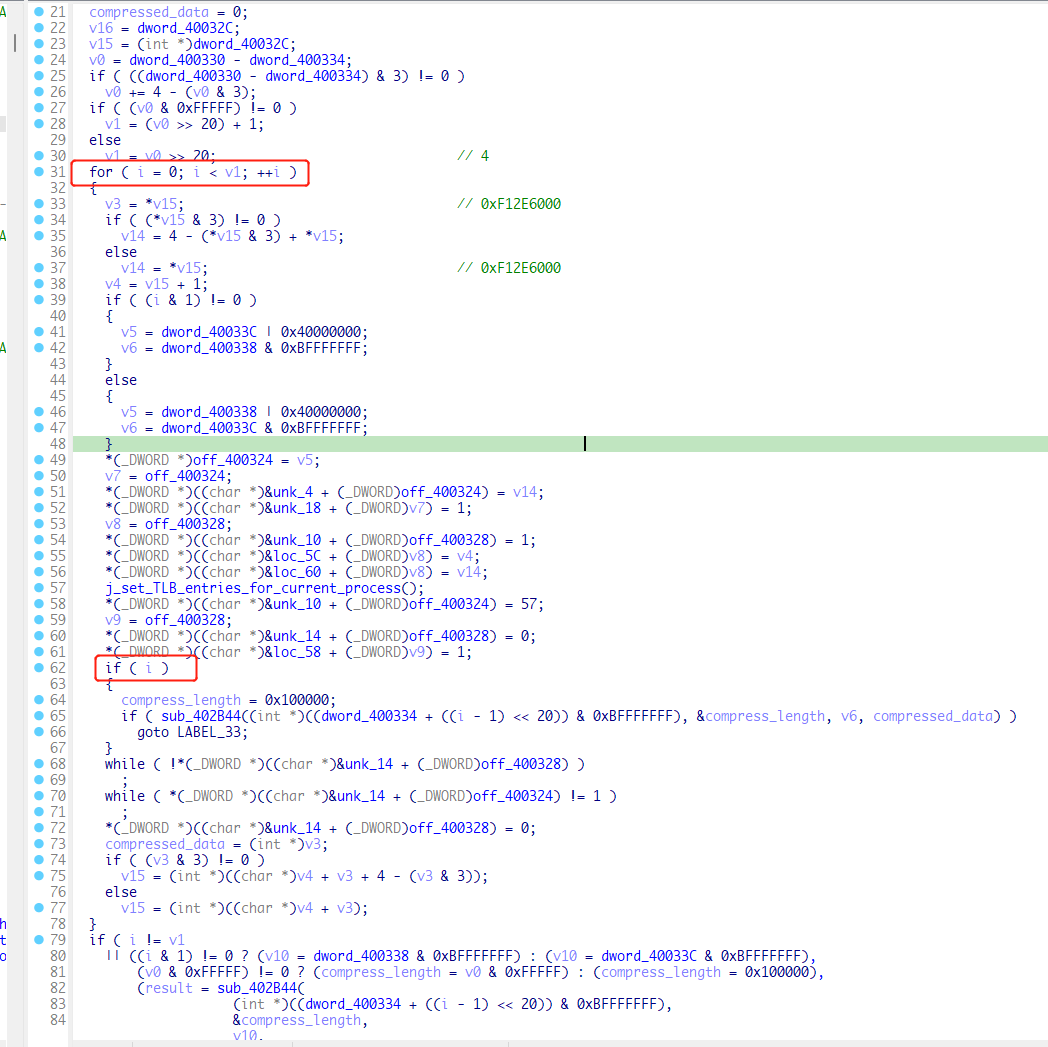
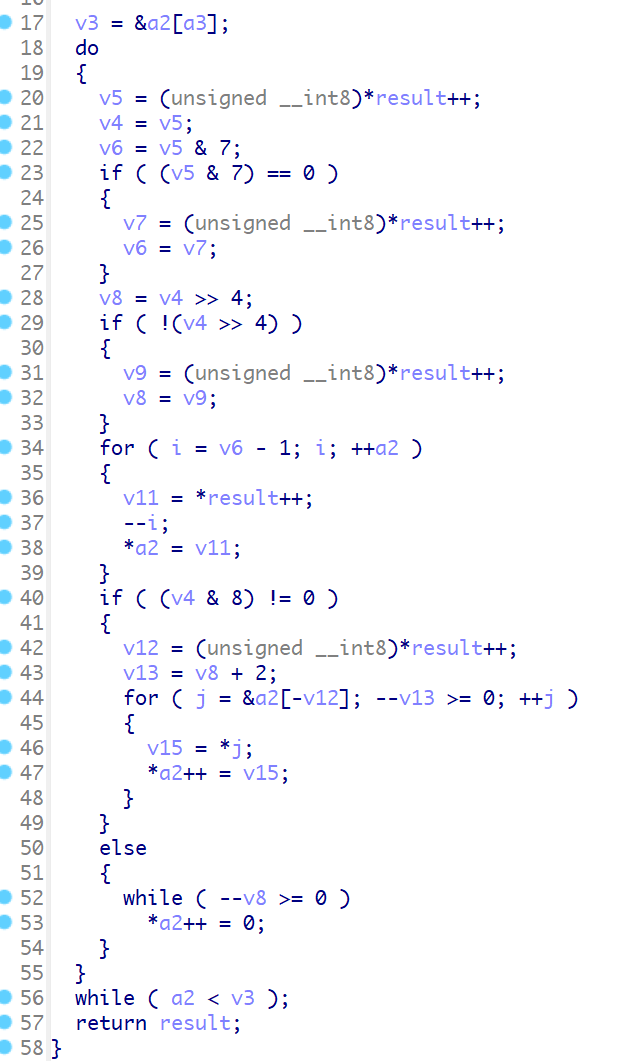
这里这个for循环的v1实际上计算出来为4,循环四次,下面进入解压缩的代码有一个if判断,i为0的时候,也就是循环的第一次实际上是不进入到解压缩的函数的
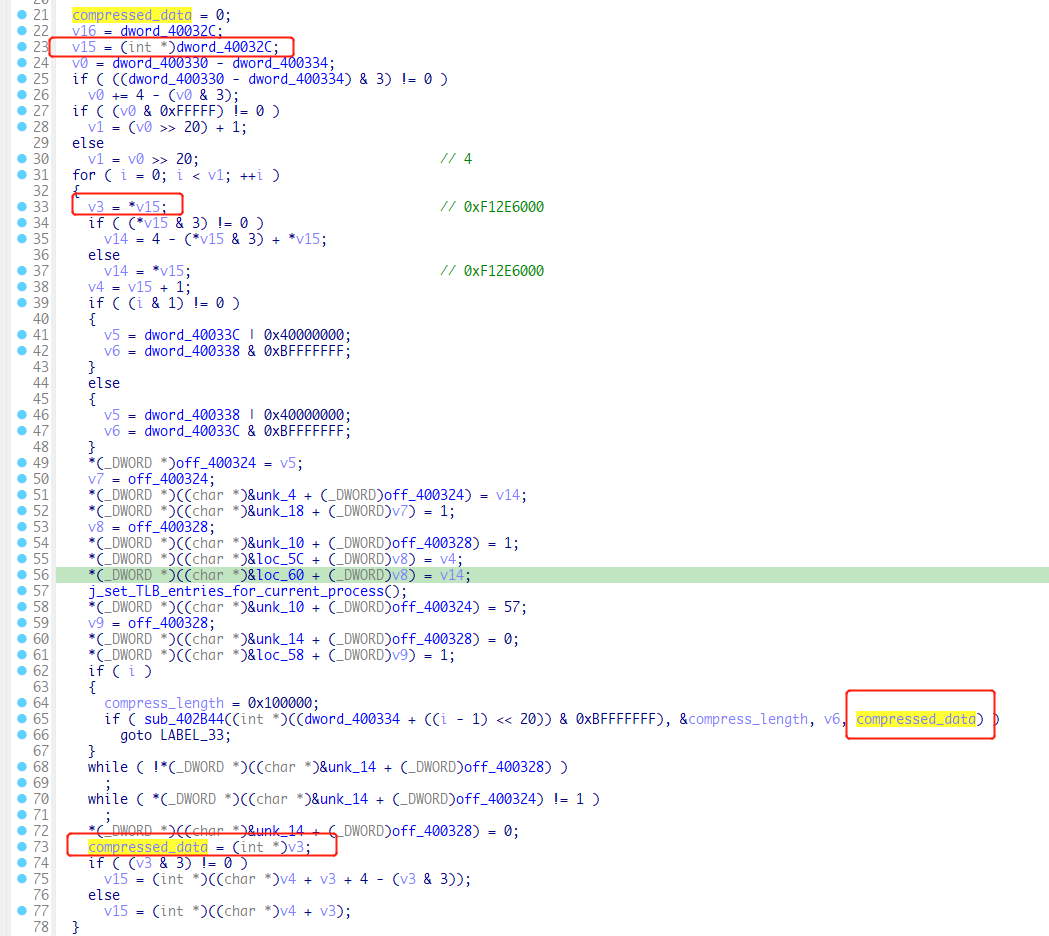
compressed_data是被压缩的数据,从i=0之后,compressed_data被赋值为v15的值,而v15如下

正是flash中偏移为0x2E6000处开始的数据

for循环中用于解压缩的函数由于i=0时不执行,所以实际上只执行了3次,每次解压缩0x10000的数据
for循环结束之后

当i=4时,有下面的代码
1 | (v0 & 0xFFFFF) != 0 ? (compress_length = v0 & 0xFFFFF) : (compress_length = 0x100000) |

v0为0x319140,所以compress_length会被更新为(compress_length = v0 & 0xFFFFF)=0x19140
也就是说前三次解压缩一共解压缩了0x300000的数据,最后一次把剩下的0x19140的数据解压缩,总共要解压缩的数据长度为0x319140
那么这个用的是什么压缩算法,binwalk看一看
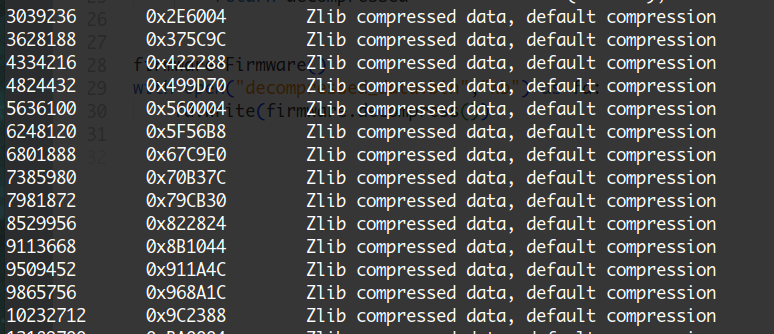
识别出来的是zlib,并且很巧,识别出来的第一个zilb压缩数据正好是在0x2E6004处,也就是在0x2E6000+4处。第二个zlib压缩包位于0x375C9C处,我们到0x2E6000处看看这四个字节

0x8fc93,zlib的起始位置为0x2E6004,0x2E6004+0x8fc93=375C97,而第二块zlib数据的起始位置为0x375C9C,0x375C9C-4=0x375C98,在循环解压缩的函数中
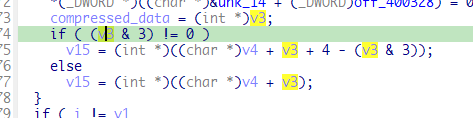
这里有一个4字节对齐的操作,因此每一个zlib压缩数据前面的4字节实际上就是压缩数据的大小,zlib数据位置加上这个size后4字节对齐就能够得到下一个zlib数据的起始位置,其格式如下
1 | [size_of_compressed_data][compressed_data] |
到这里就理清楚了解压缩的思路,写一个脚本手动对其中的数据进行解压缩
1 | import zlib |
查看一下其中的字符串
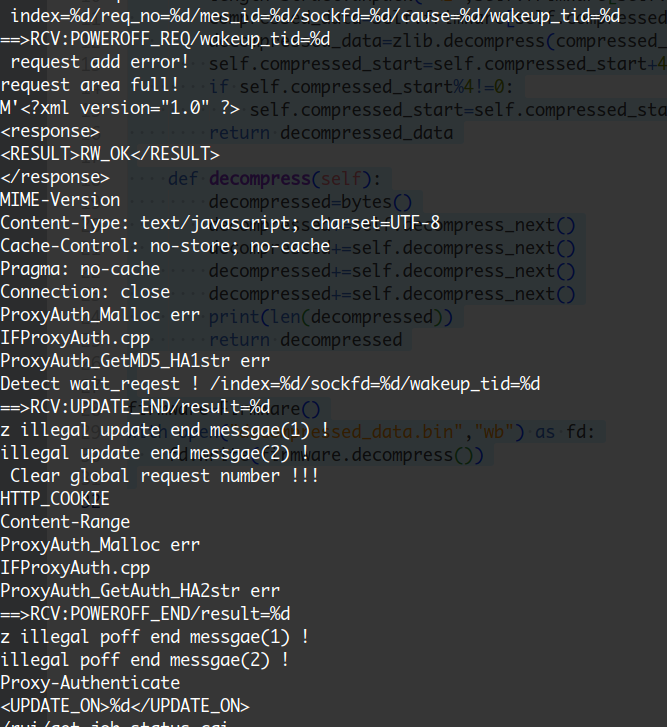
证明我们解压缩的没错。
那么这里解压缩的是什么呢,在一开始0x2e0000处执行的代码实际上就是bootloader,按照嵌入式设备一般的执行流程,bootloader会加载kernel,kernel再加载文件系统,所以这里解压缩的实际上是kernel。
kernel会被加载到哪去?
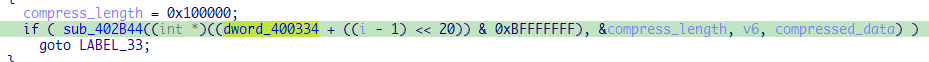
在解压缩函数中,第一个参数就是数据会被解压缩到哪个地址

1 | ((i - 1) << 20)=0xi0000 |
所以内核会从内存的0地址处开始加载
新建一个段,起始地址为0,然后将解压出来的kernel附加上去。
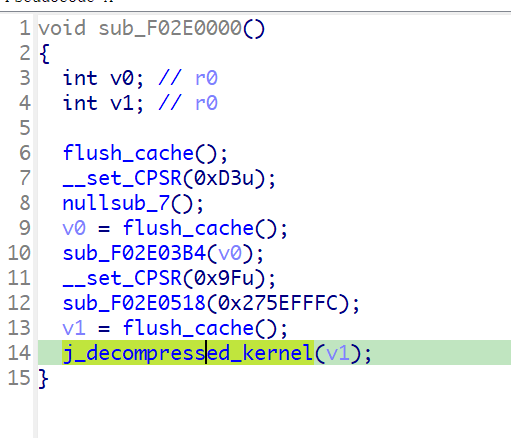
在执行完解压缩功能后,bootloader会跳转到内核去
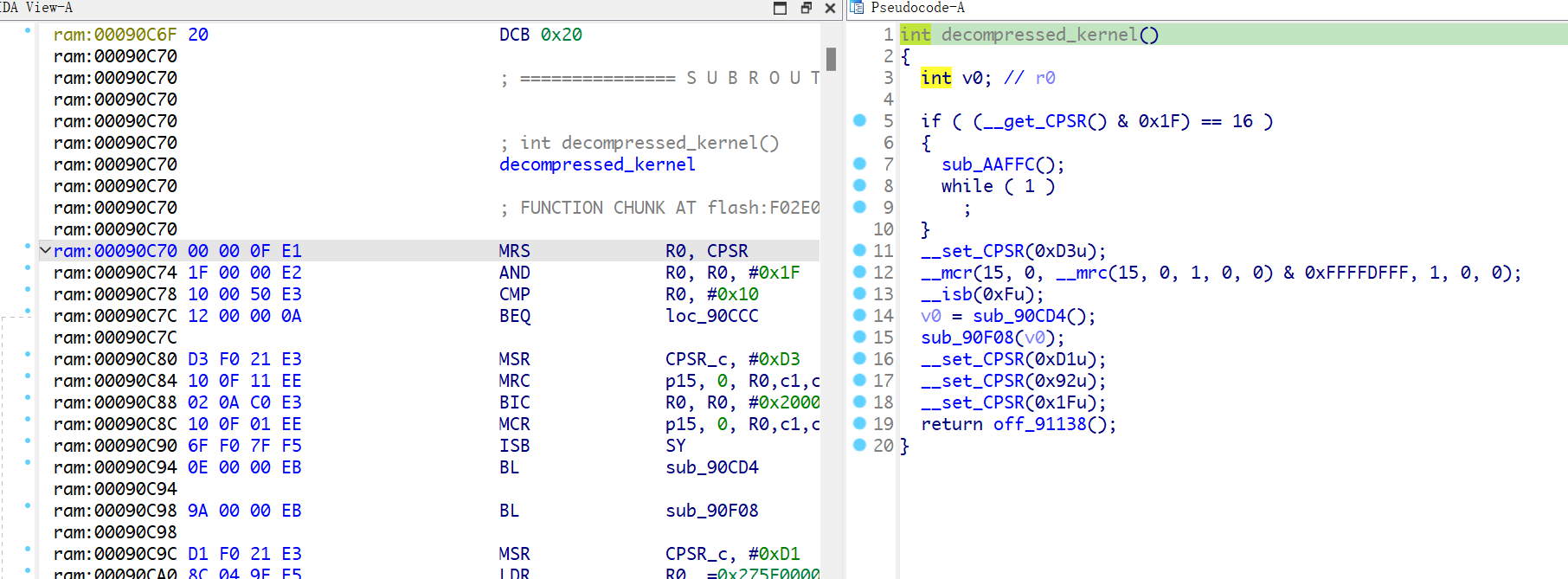
内核设置好各种系统参数和模式,然后跳转执行另外的代码



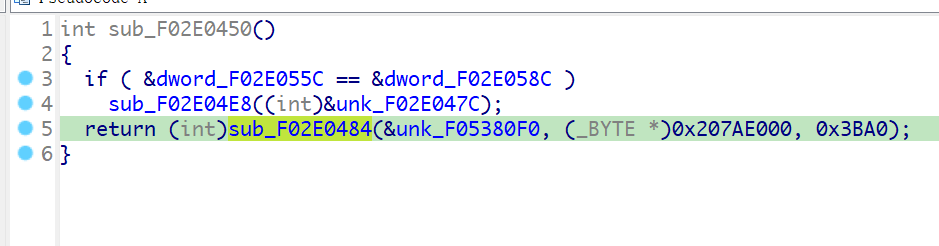
看看sub_F02E0484函数做了什么
问问万能的gpt

也就是说这个函数执行的也是解压缩功能,将a1处的数据解压缩到a2处,a3是解压缩的长度
好在IDA给出的这个函数的伪代码非常贴近于真实代码,扒下来稍微修改一下就能跑
1 |
|
不过这一段解压缩的数据太小,不像是文件系统,加载到IDA中看看

这段数据将会被加载到0x207AE000处,所以我们在这里新建一个段再加载
感觉是各种各样的指针。。没啥有意义的代码
后面的内核操作也没找到什么突破口,分析一时间陷入僵局
回头看看binwalk的结果
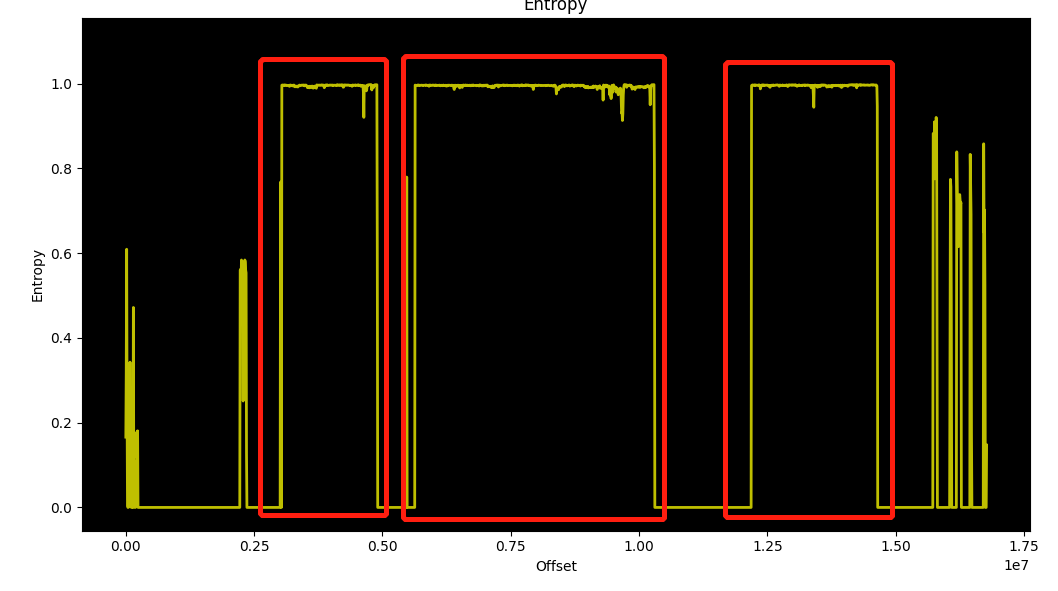
固件中有三个高熵值的区域,在一开始我们解压缩了kernel,起始位置是0x2E6000=3039232。结束位置是0x4ACFF1=4902897


而第一个高熵值区域的起始位置恰好位于3000000处,结束位置也在1900000左右,所以可以认为第一个区域就是内核段。
既然这样,第二个区域和第三个区域又是什么,这两个会在什么时候进行解压缩?
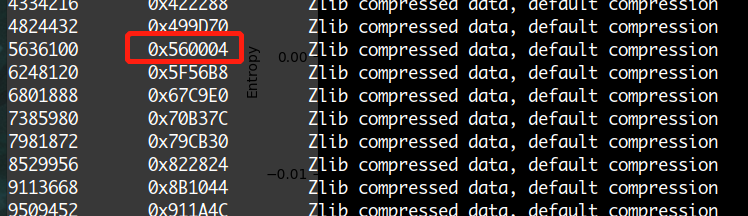
第二个区域从0x560004开始,实际上根据我们的分析,应该是从0x560000开始的,前四字节用于存储压缩数据的长度
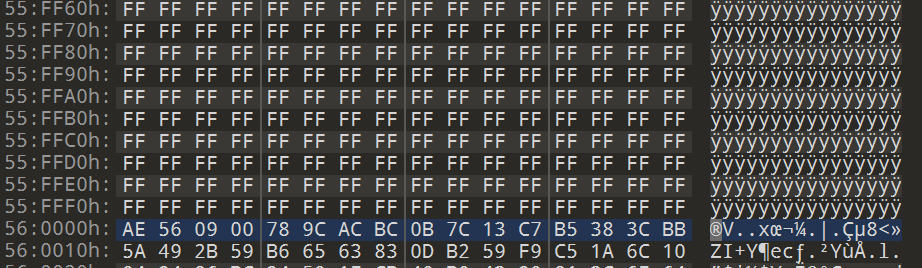
用010跳转到0x560000可以看到前面都是用0xff来隔开的。
于是尝试搜索在flash中搜索0x560000,还真搜到了一个和前面解压内核类似的函数
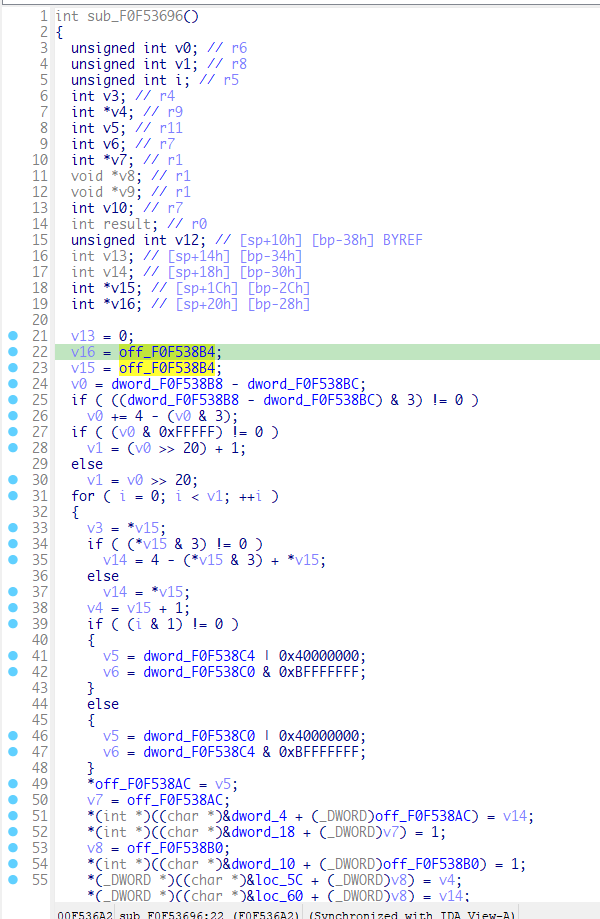
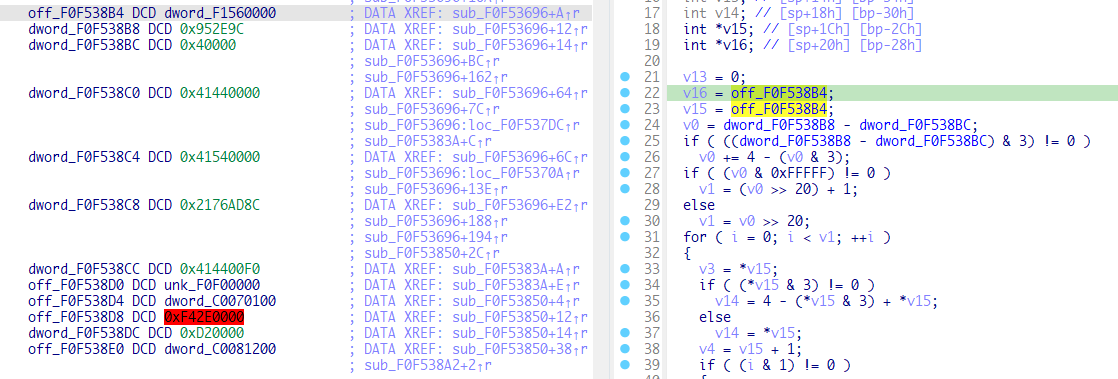
有了前面的分析,我们可以确定这个函数实际上就是将flash中从偏移为0x560000开始、长度为0x952E9C-0x40000的数据进行解压缩

将其解压缩到0x40000处。
再搜索一下0xBA0000,同样也能搜到一个解压缩函数
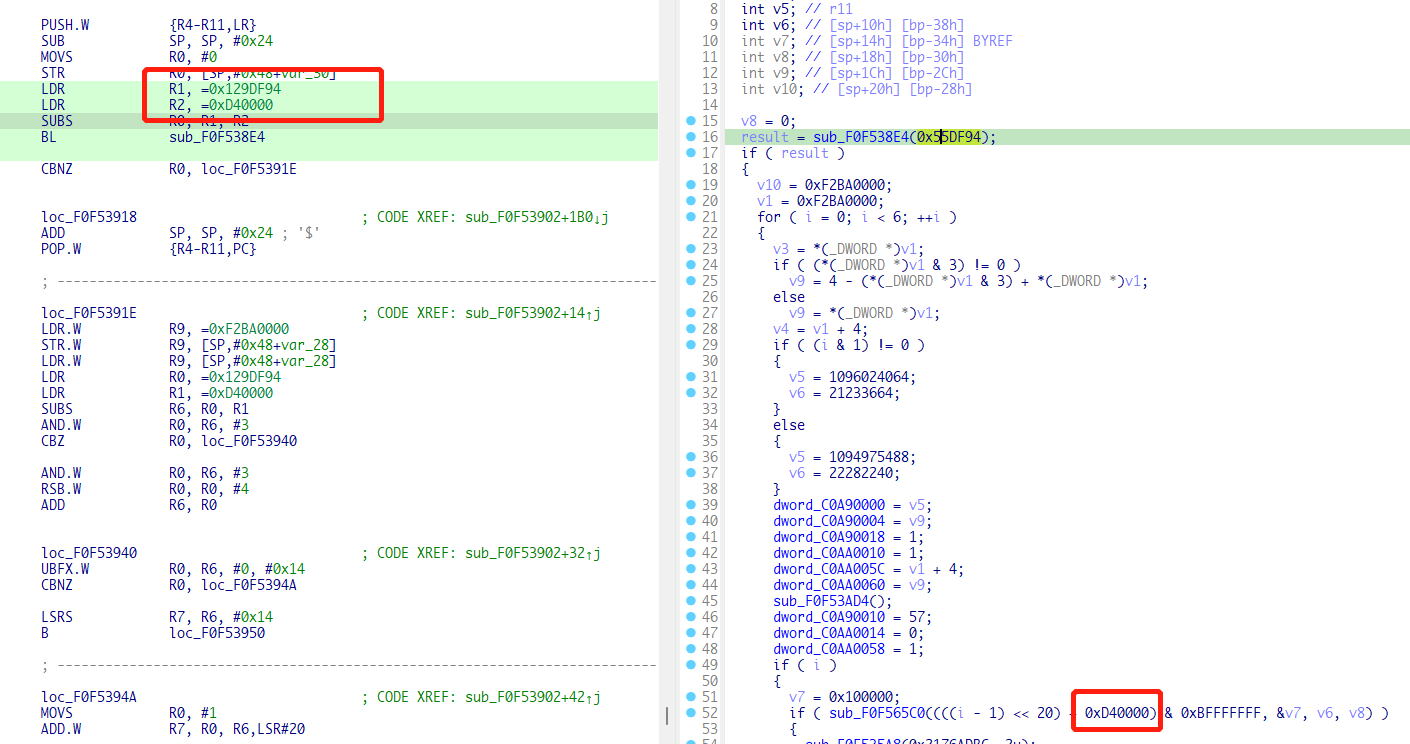
将flash中从偏移为BA0000开始、长度为0x129DF94-0xD40000的数据进行解压缩,解压地址为0xD40000
从binwalk的分析来看依然是zlib的压缩方式,所以还是按照前面的解压缩脚本进行解压缩即可
看看0x560000区域的数据解压出来的字符串
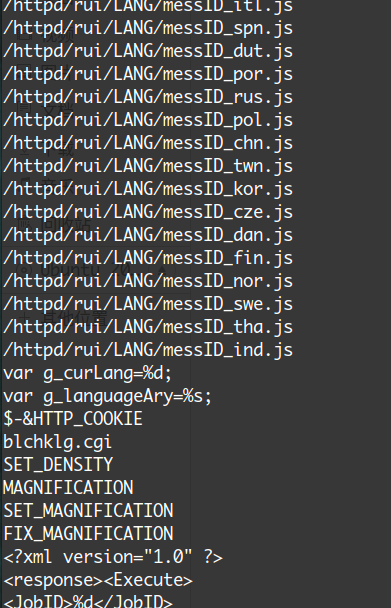
看起来很不错,应该这里就是业务代码了。再看看0xBA0000偏移的
emmmmm,看起来这些才是内核代码,或者是操作系统的代码,不管了先。
用IDA打开业务代码,加载地址设置为0x40000
有一说一,IDA恢复固件是真的差,只有一小部分被解析了

所以还是得先用ghidra来解析

ghidra基本上把整个固件都理了一遍,然后就可以在ghidra中查找感兴趣的函数,再到IDA中进行分析
佳能的固件中有不少的调试信息
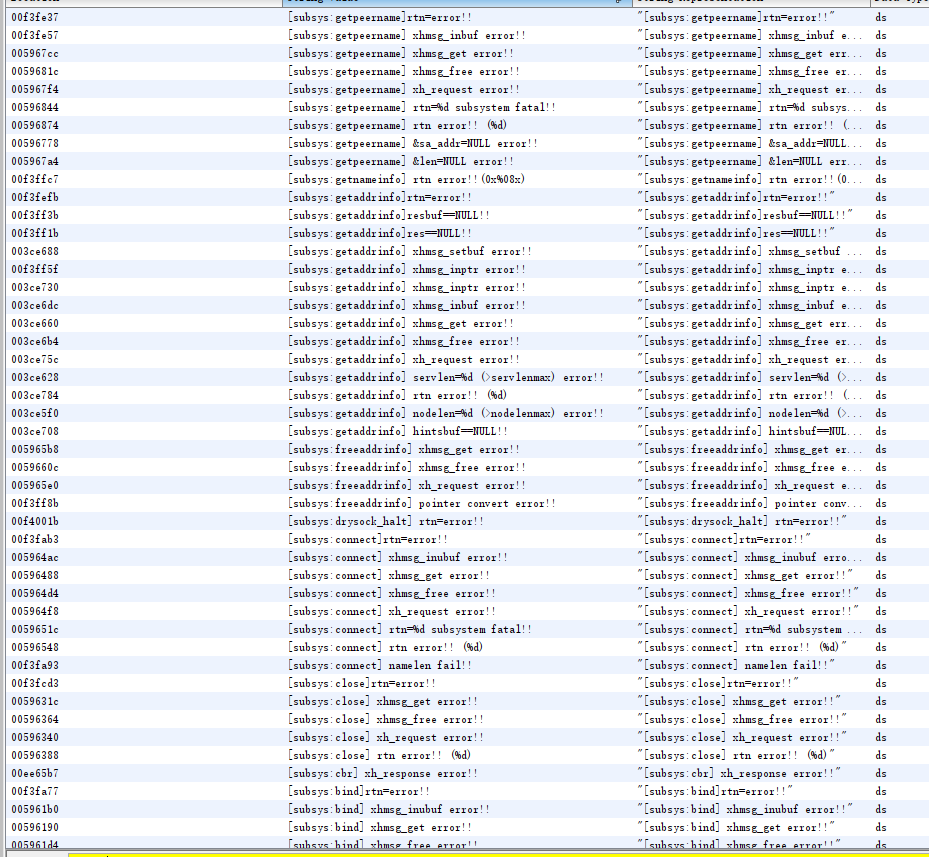
类似于[subsys:funcname],可以根据先这些调试信息来恢复一些函数名。
接下来开始找服务,一开始用nmap扫出来了不少服务,我选择从llmnr这个服务入手。
找服务的一个快捷方式就是直接搜索字符串,然后交叉引用到对应函数,在ghidra中可以找到这些字符串
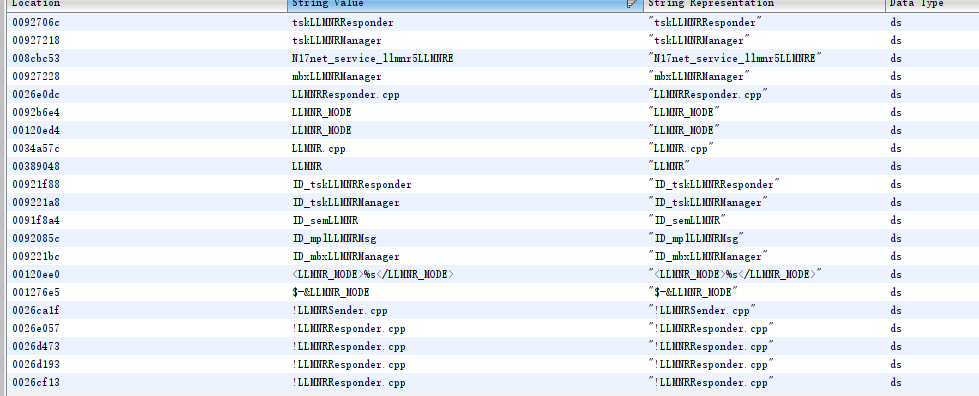
假设llmnr服务存在问题,那么问题一般存在于接收数据然后处理数据的过程中,网络接收函数一般为recv、recvmsg等等,再结合LLMNRResponder.cpp一起定位,最终交叉引用到了这个函数
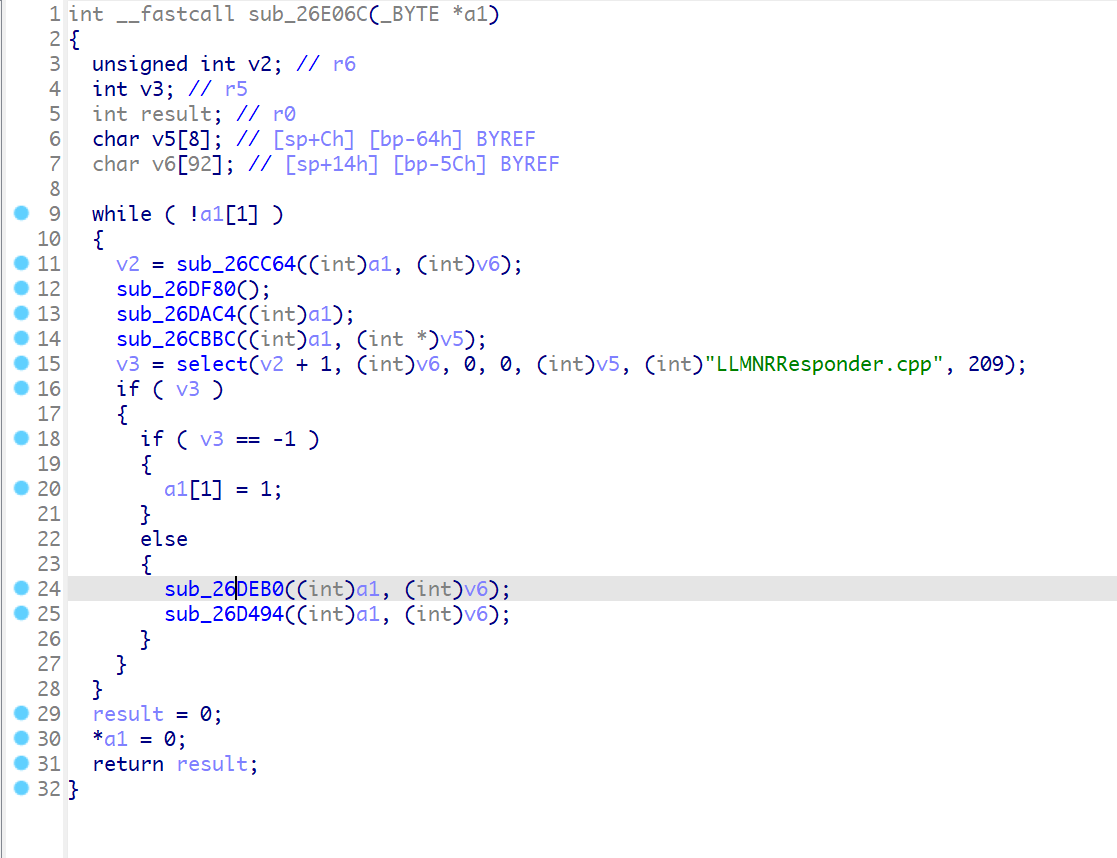
在select之前经过分析之后是LLMNRSender.cpp对应的处理函数,也就是发送响应包。
看到sub_26D494函数

有两个if判断,都是以v4为基准进行判断的,而v4来源于0x21DEE2D4,这个地址我猜测用于存储一些配置信息,两个if分别判断select到的地址是ipv4还是ipv6。
最大能够接收1500字节的数据,然后我们看到validate_llmnr_packet函数
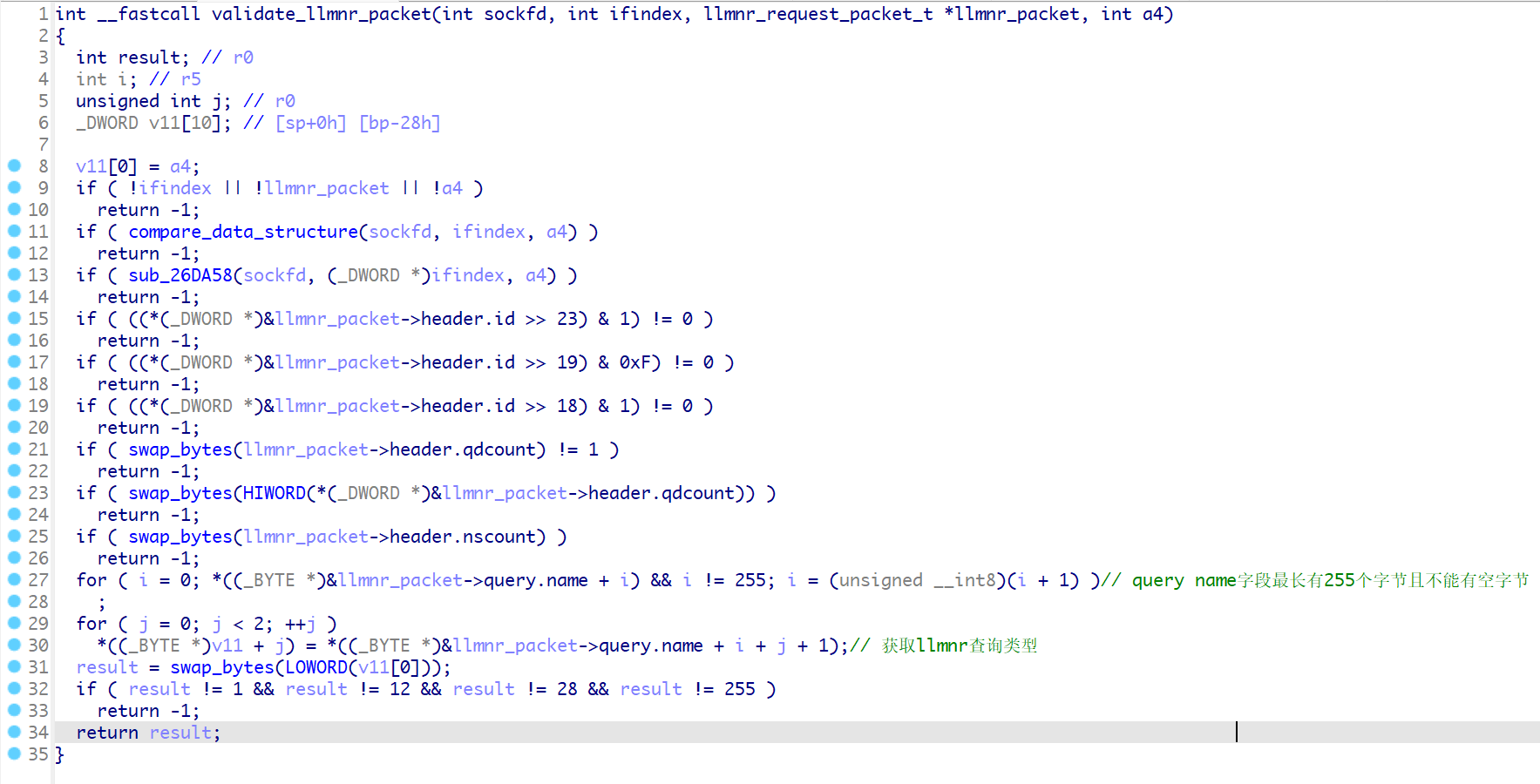
我这里创建了一个llmnr协议的结构体
1 | // LLMNR标头 |
这里就是对llmnr请求包的数据做一个判断,
其中llmnr请求中的qname字段最长只能为255字节,并且不能为空字节。
查询类型要为1,12,28,255其中一种,否则返回-1.
如果查询类型不为-1,就调用sub_26CE08函数

这里应该就是根据请求包构造出响应包,然后发送给对应主机。
看到llmnr_generate_response_packet函数

这里就是根据请求包构造响应包
假设有一个请求包如下
1 | +-----------------------+ |
那么其对应的响应包如下
1 | +-----------------------+ |
也就是说,请求包的请求头会原封不动的装入响应包中,包括请求查询的域名
calc_byte_array_length这个函数如下
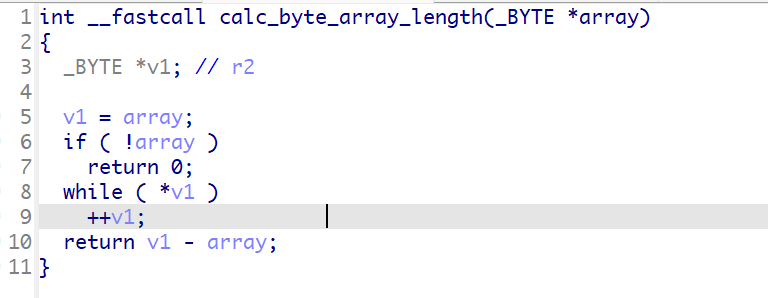
就是遍历给定的数组,一直找到空字符,也就是字符串的结尾,然后返回字符串的长度。

后面使用strncpy将请求包的query字段拷贝到响应包的字段中,拷贝长度为calc_byte_array_length计算出来的长度。
在这里的拷贝可能存在栈溢出的问题,由于calc_byte_array_length是根据空字符来判断字符串结尾的,所以字符串可以很长。
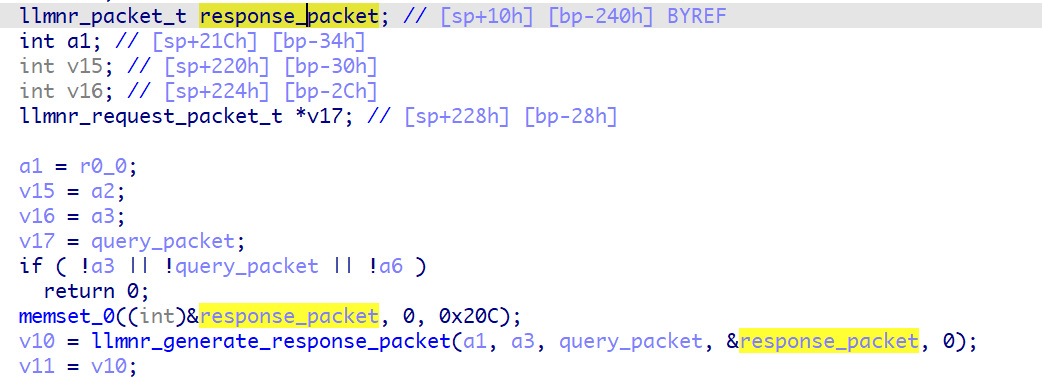
而response_packet的缓冲区只有0x20c的长度,但是query_packet最长可以有1500字节,因此只需要根据validate_llmnr_packet中的要求设置好llmnr请求包的请求字段数据。
然而在validate_llmnr_packet函数中

由于查询类型占用两字节,而查询类型又必须为1、12、28、255中的一种,所以这两字节中有一字节肯定为0,但是这样的话
在后面的calc_byte_array_length函数中,碰到0就会停下来,所以实际上后续的栈溢出是无法实现的,在类型这里就会被卡住。
非常可惜。