1.项目需求
使用C语言作为开发语言实现了一个高性能的webserver——shttpd,实现的功能有:
- select IO多路复用
- 动态配置
- CGI支持
- HTTP1.1支持
- 静态网页响应
- 文件下载
2.项目实现
2.1.项目架构
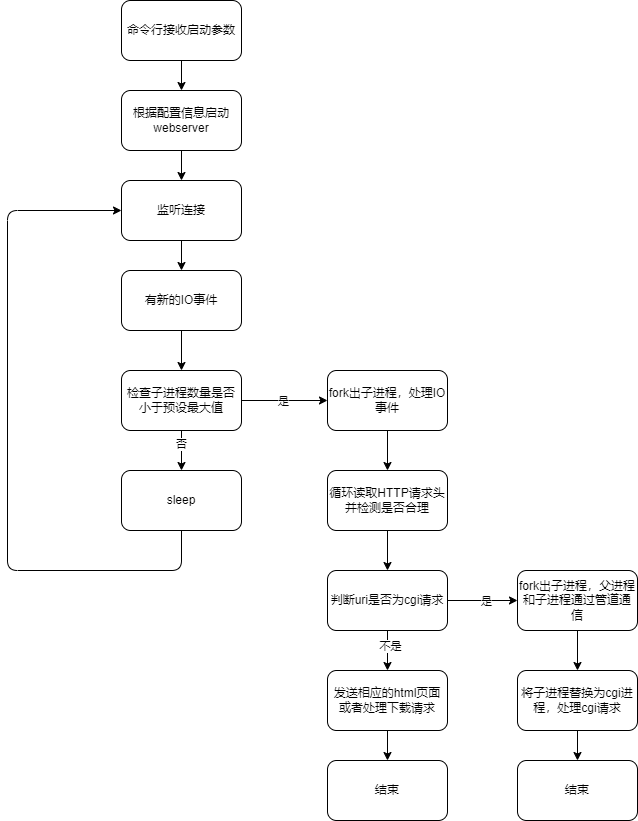
2.2 动态配置
shttpd使用命令行函数getopt_long接受简易的参数设定,如web根目录,cgi目录,开放端口以及最大客户端数量。
2.3 启动服务器
通过socket-bind-listen-accept启动服务器
2.4 网络事件处理
使用select处理网络事件请求,为每一个请求分配一个子进程进行处理,如果此时子进程的数量大于预设的最大值就sleep,暂不处理请求;在父进程中使用waitpid回收子进程,父进程永不退出。
2.5 HTTP请求解析
使用fgets遇到\n就停止读取的特性,循环读取HTTP请求的每一行,以空格将每一行进行分割提取值,并判断其是否合法;由于对于每个网络请求都分配一个子进程,因此使用全局变量来保存读取到的HTTP请求头的值,无需担心不同进程间出现干扰。提取完所有的请求头之后,判断请求方式,如果是POST请求则根据content-length字段的值来读取相应大小的content;接下来判断url是否为cgi请求,如果是普通文件则进入到文件发送的流程,如果为cgi请求则进入到cgi处理流程。
2.5.1 文件发送流程
在文件发送流程中,首先根据请求的文件类型设定好响应头中的content-type;然后生成ETAG字段,比较请求头中的ETAG字段和此时生成的ETAG字段是否相同,相同的话则发送Not Modified响应;如果请求头中存在IfModifiedSince字段,则解析该字段为unix时间戳,和请求文件的最后修改时间戳进行比较,如果请求文件的最后修改时间戳大于等于IfModifiedSince字段的时间戳,则也发送Not Modified响应;接下来再打开请求文件,如果有Range字段,则根据Range字段发送相应大小的文件数据,如果没有则完整发送文件;发送文件使用sendfile零拷贝函数,直接在内核中进行拷贝,避免在用户态和内核态之间操作数据,提高效率。
2.5.2 CGI处理流程
如果是cgi请求,首先创建一个读管道in[2],一个写管道out[2],然后fork出子进程,子进程也会继承读写管道。
父进程将数据通过管道发送给cgi子进程,cgi子进程处理完请求之后通过管道将结果写回给父进程,管道示意图如下所示
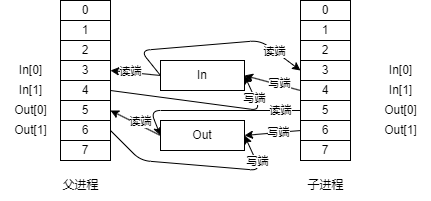
上图是fork出子进程之后的管道图,还需要关闭不需要的管道描述符。
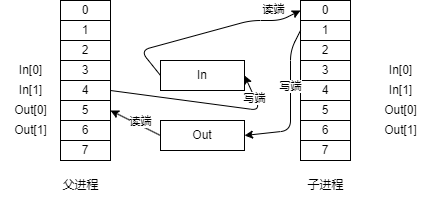
这里的In和Out两个管道都是相对于子进程而言的,将子进程的In的读端重定向到标准输入,将写端重定向到标准输出,这样就可以通过printf等标准输出输入函数直接从父进程中读取数据或者往父进程中写入数据。
CGI程序从环境变量中获取数据,因此在执行cgi之前,还需要设置好环境变量,然后调用execl系列函数启动cgi程序
3.项目效果
项目内嵌了3个html页面和一个用于测试的cgi程序,访问默认端口会返回index.html页面
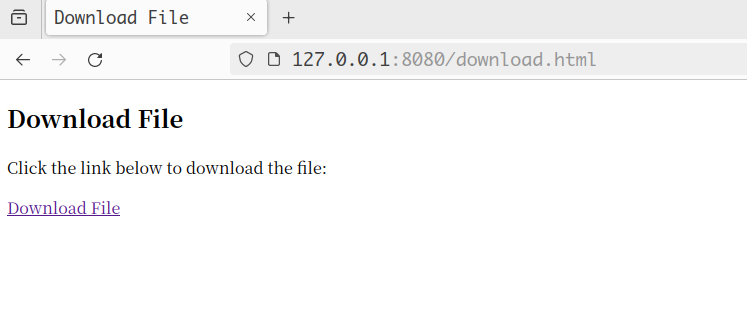
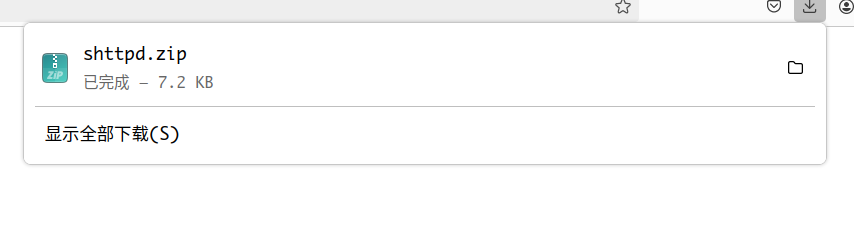
访问download.html会返回下载页面,点击下载链接会下载一个压缩包
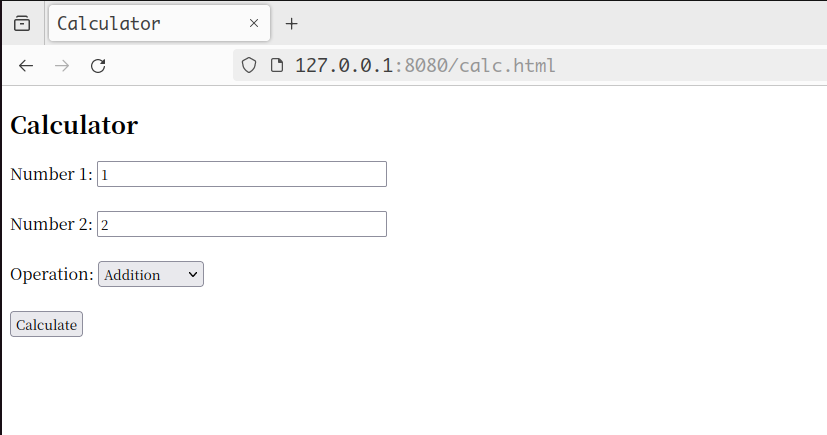
访问calc.html用于调用后端的cgi
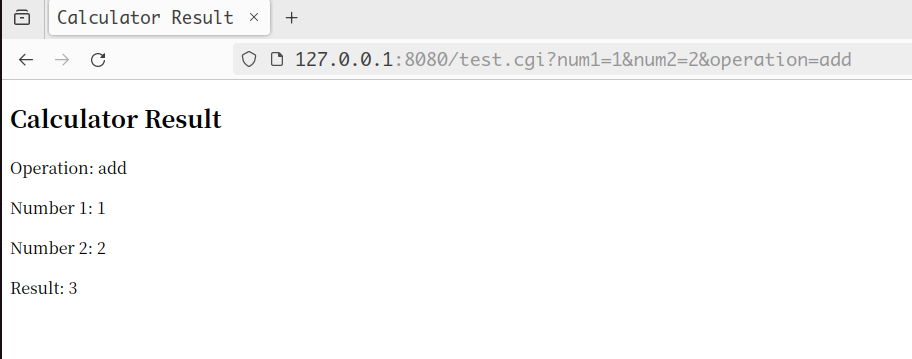
cgi实现了简单的加减法功能,计算完毕后会将结果返回到浏览器中
4.压力测试
使用webbench进程压力测试
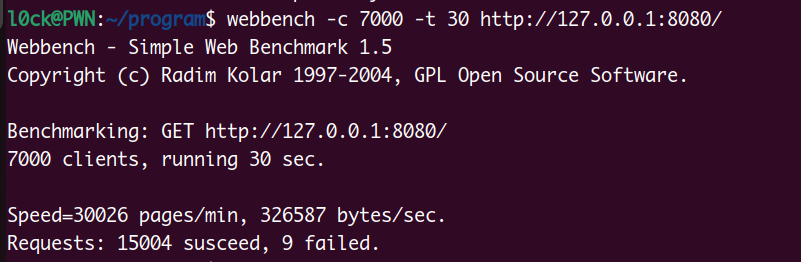
使用7000并发量测试30s,存在9个failed
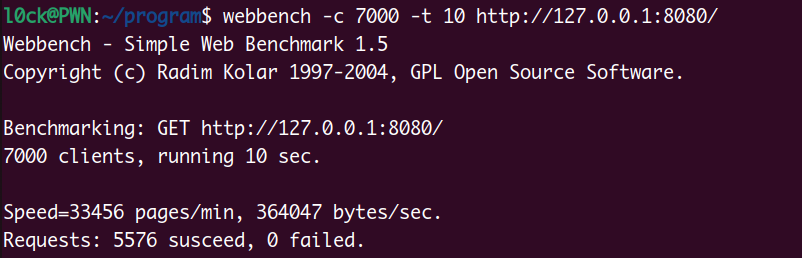
使用7000并发量测试10s,全部通过
也可以通过-m参数指定webserver的最大并发量,默认是50,将其设置为100
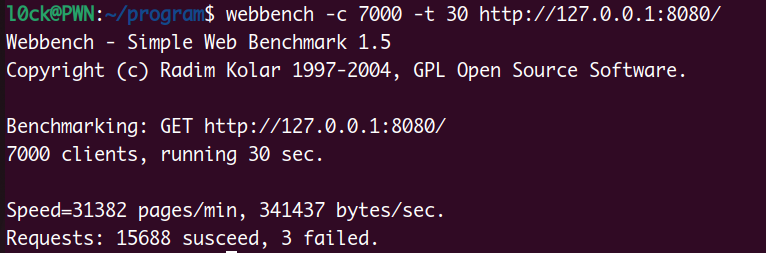
有所提升,不过并发量不能设置太大,因为每一个并发都是一个子进程,对系统资源是很大的占用。
5.系统资源占用
没有访问的情况下,shttpd对CPU资源的占用量极低
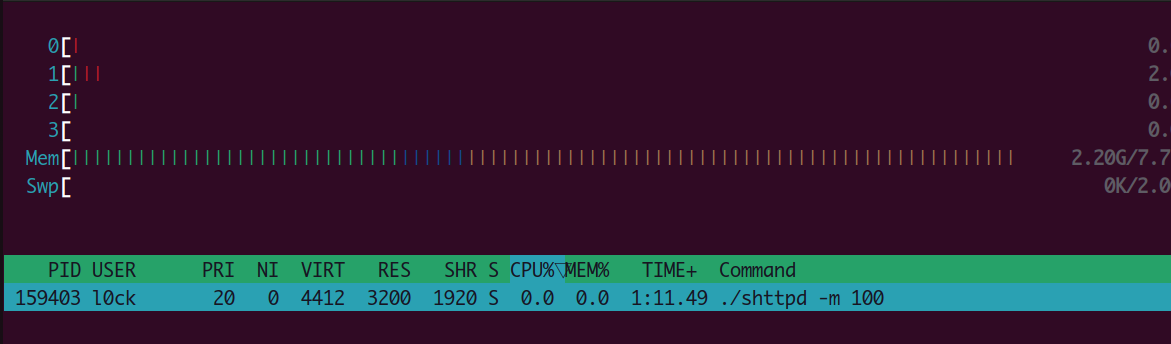
在使用webbench测试时,占用量如下
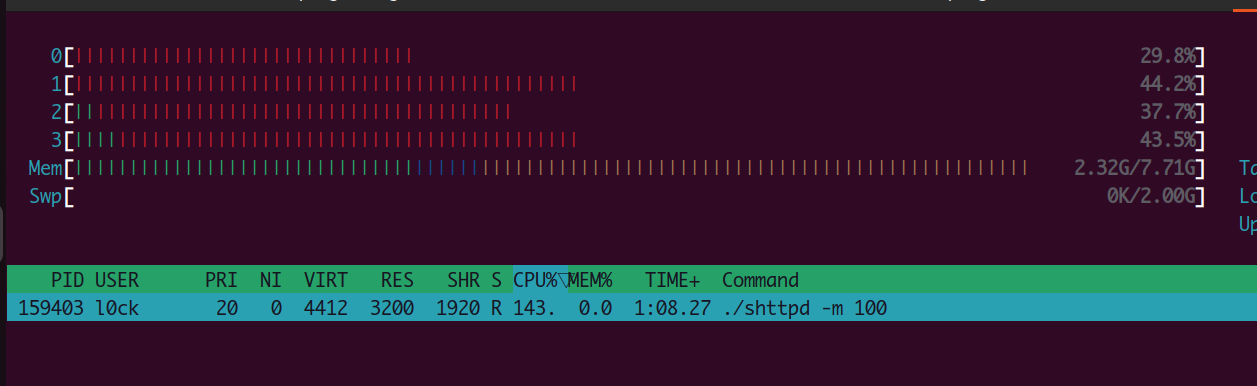
限制shttpd并发量为100,webbench并发量为7000。
可以看到对于内存的占用实际上也没有那么多,从2.20G增长到了2.32G