1.string分析
以下面的代码作为例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include <iostream>
#include <string>
#include <stdlib.h>
using namespace std;
int main(int argc, char const *argv[])
{
string str;
for (int i = 0; i < 0x200; i++)
{
str += 'a';
std::cout << "size : " << str.size() << " capacity : " << str.capacity() << std::endl;
}
return 0;
}
|
结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
| size : 1 capacity : 15
size : 2 capacity : 15
size : 3 capacity : 15
size : 4 capacity : 15
size : 5 capacity : 15
size : 6 capacity : 15
size : 7 capacity : 15
size : 8 capacity : 15
size : 9 capacity : 15
size : 10 capacity : 15
size : 11 capacity : 15
size : 12 capacity : 15
size : 13 capacity : 15
size : 14 capacity : 15
size : 15 capacity : 15
size : 16 capacity : 31
size : 17 capacity : 31
size : 18 capacity : 31
size : 19 capacity : 31
size : 20 capacity : 31
size : 21 capacity : 31
size : 22 capacity : 31
size : 23 capacity : 31
size : 24 capacity : 31
size : 25 capacity : 31
size : 26 capacity : 31
size : 27 capacity : 31
size : 28 capacity : 31
size : 29 capacity : 31
size : 30 capacity : 31
size : 31 capacity : 31
size : 32 capacity : 47
size : 33 capacity : 47
size : 34 capacity : 47
size : 35 capacity : 47
size : 36 capacity : 47
size : 37 capacity : 47
size : 38 capacity : 47
size : 39 capacity : 47
size : 40 capacity : 47
size : 41 capacity : 47
size : 42 capacity : 47
size : 43 capacity : 47
size : 44 capacity : 47
size : 45 capacity : 47
size : 46 capacity : 47
size : 47 capacity : 47
size : 48 capacity : 70
size : 49 capacity : 70
size : 50 capacity : 70
size : 51 capacity : 70
size : 52 capacity : 70
size : 53 capacity : 70
size : 54 capacity : 70
size : 55 capacity : 70
size : 56 capacity : 70
size : 57 capacity : 70
size : 58 capacity : 70
size : 59 capacity : 70
size : 60 capacity : 70
size : 61 capacity : 70
size : 62 capacity : 70
size : 63 capacity : 70
size : 64 capacity : 70
size : 65 capacity : 70
size : 66 capacity : 70
size : 67 capacity : 70
size : 68 capacity : 70
size : 69 capacity : 70
size : 70 capacity : 70
size : 71 capacity : 105
size : 72 capacity : 105
size : 73 capacity : 105
size : 74 capacity : 105
size : 75 capacity : 105
size : 76 capacity : 105
size : 77 capacity : 105
size : 78 capacity : 105
size : 79 capacity : 105
size : 80 capacity : 105
size : 81 capacity : 105
size : 82 capacity : 105
size : 83 capacity : 105
size : 84 capacity : 105
size : 85 capacity : 105
size : 86 capacity : 105
size : 87 capacity : 105
size : 88 capacity : 105
size : 89 capacity : 105
size : 90 capacity : 105
size : 91 capacity : 105
size : 92 capacity : 105
size : 93 capacity : 105
size : 94 capacity : 105
size : 95 capacity : 105
size : 96 capacity : 105
size : 97 capacity : 105
size : 98 capacity : 105
size : 99 capacity : 105
size : 100 capacity : 105
......
|
其实分析过Linux下的string机制的话,对string类是有一个大致的了解的,在str长度小于0x10的时候,string类是存储在栈上的,当长度超过0x10的时候,就会在堆上申请内存,将字符串存到堆上。
具体调试一下,初始化之后,str是存在栈上的
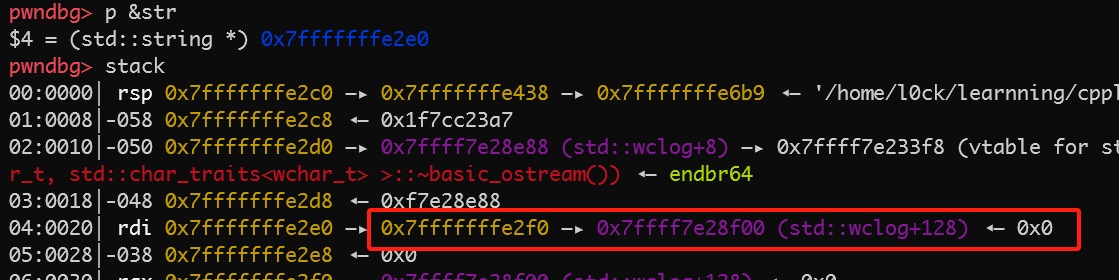

红框处的值只是栈中残留的数据,不是string类真实的数据,string类开头的八字节指向红框处,当有了字符串之后,如下图所示

开头8字节指向字符串,第二个八字节为字符串的长度,字符串末尾以00结尾。
当字符串长度大于等于0x10之后,如下图所示

开头八字节指向堆了,这个堆的大小为0x30

观察输出:
1
2
| size : 31 capacity : 31
size : 32 capacity : 47
|
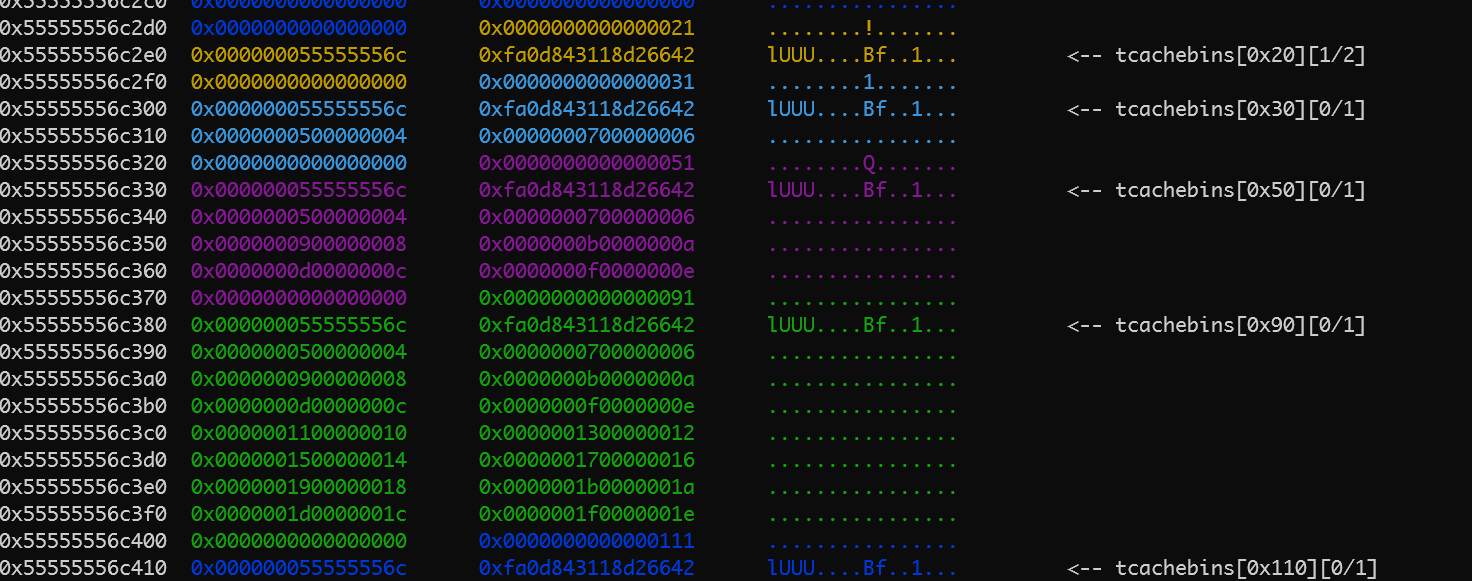
当size为31时,加上末尾的00字节,此时的size为0x20,和capacity大小一致,结合glibc的堆块管理机制,可以推断第一次从堆中申请内存的大小为0x20,ptmalloc会返回0x30大小的堆块。
整个程序运行结束之后,堆的情况如下所示
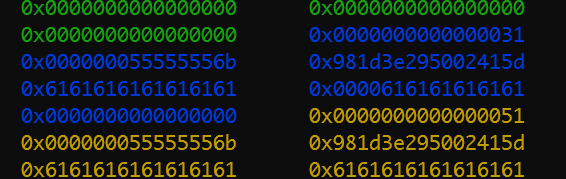
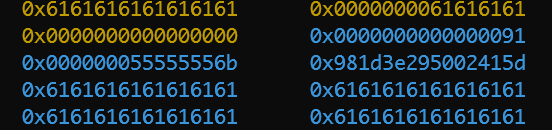
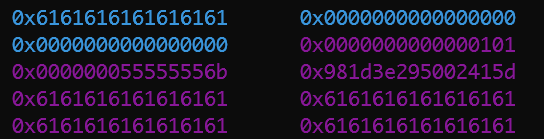
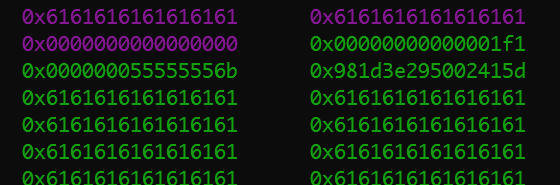
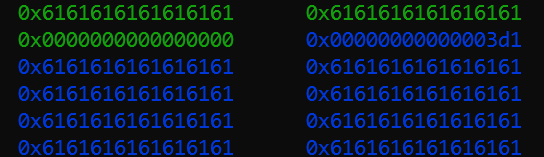
0x30->0x50->0x90->0x100->0x1f0->0x3d0,可以看出,堆内存有效数据的扩容大致两倍的扩容的。如malloc(0x20*2)=0x50,malloc(0x40*2)=0x90,malloc(0x80*2)=0x110,malloc(0xf0*2)=0x1f0,malloc(0x1e0*2)=0x3d0
不过在Windows下的扩容机制和Linux下稍有区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
| size : 1 capacity : 15
size : 2 capacity : 15
size : 3 capacity : 15
size : 4 capacity : 15
size : 5 capacity : 15
size : 6 capacity : 15
size : 7 capacity : 15
size : 8 capacity : 15
size : 9 capacity : 15
size : 10 capacity : 15
size : 11 capacity : 15
size : 12 capacity : 15
size : 13 capacity : 15
size : 14 capacity : 15
size : 15 capacity : 15
size : 16 capacity : 31
size : 17 capacity : 31
size : 18 capacity : 31
size : 19 capacity : 31
size : 20 capacity : 31
size : 21 capacity : 31
size : 22 capacity : 31
size : 23 capacity : 31
size : 24 capacity : 31
size : 25 capacity : 31
size : 26 capacity : 31
size : 27 capacity : 31
size : 28 capacity : 31
size : 29 capacity : 31
size : 30 capacity : 31
size : 31 capacity : 31
size : 32 capacity : 47
size : 33 capacity : 47
size : 34 capacity : 47
size : 35 capacity : 47
size : 36 capacity : 47
size : 37 capacity : 47
size : 38 capacity : 47
size : 39 capacity : 47
size : 40 capacity : 47
size : 41 capacity : 47
size : 42 capacity : 47
size : 43 capacity : 47
size : 44 capacity : 47
size : 45 capacity : 47
size : 46 capacity : 47
size : 47 capacity : 47
size : 48 capacity : 70
size : 49 capacity : 70
size : 50 capacity : 70
size : 51 capacity : 70
size : 52 capacity : 70
size : 53 capacity : 70
size : 54 capacity : 70
size : 55 capacity : 70
size : 56 capacity : 70
size : 57 capacity : 70
size : 58 capacity : 70
size : 59 capacity : 70
size : 60 capacity : 70
size : 61 capacity : 70
size : 62 capacity : 70
size : 63 capacity : 70
size : 64 capacity : 70
size : 65 capacity : 70
size : 66 capacity : 70
size : 67 capacity : 70
size : 68 capacity : 70
size : 69 capacity : 70
size : 70 capacity : 70
size : 71 capacity : 105
size : 72 capacity : 105
size : 73 capacity : 105
size : 74 capacity : 105
size : 75 capacity : 105
size : 76 capacity : 105
size : 77 capacity : 105
size : 78 capacity : 105
size : 79 capacity : 105
size : 80 capacity : 105
size : 81 capacity : 105
size : 82 capacity : 105
size : 83 capacity : 105
size : 84 capacity : 105
size : 85 capacity : 105
size : 86 capacity : 105
size : 87 capacity : 105
size : 88 capacity : 105
size : 89 capacity : 105
size : 90 capacity : 105
size : 91 capacity : 105
size : 92 capacity : 105
size : 93 capacity : 105
size : 94 capacity : 105
size : 95 capacity : 105
size : 96 capacity : 105
size : 97 capacity : 105
size : 98 capacity : 105
size : 99 capacity : 105
size : 100 capacity : 105
......
|
Windows下string类按照1.5倍扩容
string的扩容机制源码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| size_type _Grow_to(size_type _Count) const
{
size_type _Capacity = capacity();
if ( _Capacity < 32 ) {
_Capacity = _Capacity + 16;
}else {
_Capacity = max_size() - _Capacity / 2 < _Capacity
? 0 : _Capacity + _Capacity / 2;
}
if (_Capacity < _Count)
_Capacity = _Count;
return (_Capacity);
}
|
基本而言就是每次增加上一次Capacity的1.5倍。
再使用如下程序进入IDA分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include <iostream>
#include <string>
using namespace std;
int main() {
std::string str1;
std::string str2("Hello, World!");
std::string str3(str2);
std::string str4(std::move(str2));
str1 = str3;
str2 = " Assigned String";
str3 = std::move(str1);
std::cout << "Length of str3: " << str3.length() << std::endl;
std::cout << "First character of str3: " << str3[0] << std::endl;
str3 += " and more";
size_t pos = str3.find("and");
if (pos != std::string::npos) {
std::cout << "Found 'and' at position: " << pos << std::endl;
}
std::string str5 = "Hello";
std::string str6 = "Hello";
if (str5.compare(str6) == 0) {
std::cout << "str5 and str6 are equal." << std::endl;
}
std::cout << "Enter a string: ";
std::getline(std::cin, str1);
std::cout << "You entered: " << str1 << std::endl;
return 0;
}
|
IDA的反编译结果如下

直接创建空的string类使用std::string::basic_string,根据字符串来创建类会先初始化一个std::allocator<char>::allocator()的类,然后再根据字符串创建string类,根据string类来创建string也是使用std::string::basic_string,根据move来创建string也很清楚,先调用std::move<std::string &>对string进行move,然后再使用std::string::basic_string来创建类。

string类的赋值使用的是std::string::operator=(str1,str3),将str3赋值给str1,又或者将字符串赋值给str1.

使用std::string::operator[]来取地址,第一个参数是string,第二个参数是要取的地址的索引。
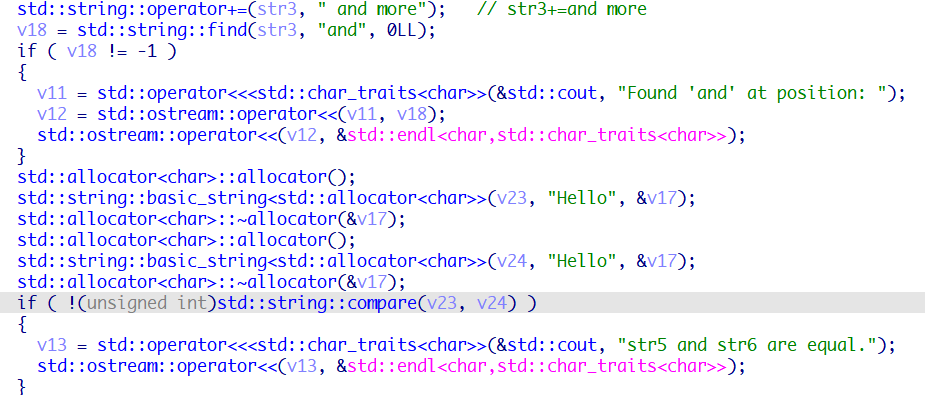
使用std::string::operator+=()来完成字符串的拼接。
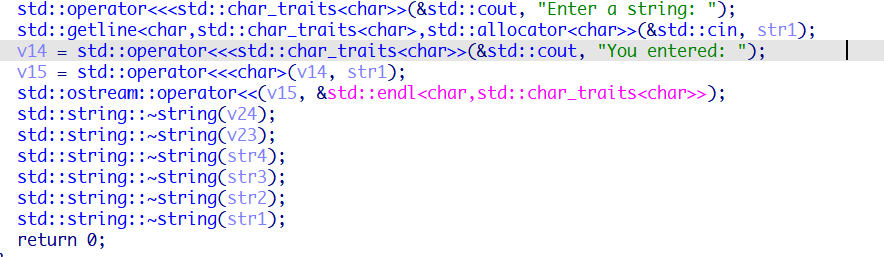
在返回之前调用析构函数,结束string类的生命周期。
2.vector分析
首先还是分析一下vector的扩容原则
例子如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| #include<iostream>
#include<vector>
using namespace std;
int main(int argc, char** argv) {
std::vector<int> a;
int num[16];
for (int i = 0; i < 100; i++) {
a.push_back(i);
std::cout << "size : " << i + 1 << "\t" << "capacity : " << a.capacity() << std::endl;
}
system("pause");
return 0;
}
|
Linux下输出如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| size : 1 capacity : 1
size : 2 capacity : 2
size : 3 capacity : 4
size : 4 capacity : 4
size : 5 capacity : 8
size : 6 capacity : 8
size : 7 capacity : 8
size : 8 capacity : 8
size : 9 capacity : 16
size : 10 capacity : 16
size : 11 capacity : 16
size : 12 capacity : 16
size : 13 capacity : 16
size : 14 capacity : 16
size : 15 capacity : 16
size : 16 capacity : 16
size : 17 capacity : 32
size : 18 capacity : 32
size : 19 capacity : 32
size : 20 capacity : 32
size : 21 capacity : 32
size : 22 capacity : 32
size : 23 capacity : 32
size : 24 capacity : 32
size : 25 capacity : 32
size : 26 capacity : 32
size : 27 capacity : 32
size : 28 capacity : 32
size : 29 capacity : 32
size : 30 capacity : 32
size : 31 capacity : 32
size : 32 capacity : 32
size : 33 capacity : 64
size : 34 capacity : 64
size : 35 capacity : 64
size : 36 capacity : 64
size : 37 capacity : 64
size : 38 capacity : 64
size : 39 capacity : 64
size : 40 capacity : 64
size : 41 capacity : 64
size : 42 capacity : 64
size : 43 capacity : 64
size : 44 capacity : 64
size : 45 capacity : 64
size : 46 capacity : 64
size : 47 capacity : 64
size : 48 capacity : 64
|
很明显也是按照2倍大小扩容
在gdb中调试,查看堆的大小,也是符合2倍扩容的机制的。
在Windows下和Linux下的又稍有不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| size : 1 capacity : 1
size : 2 capacity : 2
size : 3 capacity : 3
size : 4 capacity : 4
size : 5 capacity : 6
size : 6 capacity : 6
size : 7 capacity : 9
size : 8 capacity : 9
size : 9 capacity : 9
size : 10 capacity : 13
size : 11 capacity : 13
size : 12 capacity : 13
size : 13 capacity : 13
size : 14 capacity : 19
size : 15 capacity : 19
size : 16 capacity : 19
size : 17 capacity : 19
size : 18 capacity : 19
size : 19 capacity : 19
size : 20 capacity : 28
size : 21 capacity : 28
size : 22 capacity : 28
size : 23 capacity : 28
size : 24 capacity : 28
size : 25 capacity : 28
size : 26 capacity : 28
size : 27 capacity : 28
size : 28 capacity : 28
size : 29 capacity : 42
size : 30 capacity : 42
size : 31 capacity : 42
size : 32 capacity : 42
size : 33 capacity : 42
size : 34 capacity : 42
size : 35 capacity : 42
size : 36 capacity : 42
size : 37 capacity : 42
size : 38 capacity : 42
size : 39 capacity : 42
size : 40 capacity : 42
size : 41 capacity : 42
size : 42 capacity : 42
size : 43 capacity : 63
size : 44 capacity : 63
size : 45 capacity : 63
size : 46 capacity : 63
size : 47 capacity : 63
size : 48 capacity : 63
size : 49 capacity : 63
size : 50 capacity : 63
size : 51 capacity : 63
size : 52 capacity : 63
size : 53 capacity : 63
size : 54 capacity : 63
|
除了一开始的容量变化是
1
2
3
4
| size : 1 capacity : 1
size : 2 capacity : 2
size : 3 capacity : 3
size : 4 capacity : 4
|
1,2,3,4不是1.5倍的增长率,后续的增长也是1.5倍的增长,源码为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| else if (max_size() - size() < _Count)
_Xlen();
else if (_Capacity < size() + _Count){
_Capacity = max_size() - _Capacity / 2 < _Capacity
? 0 : _Capacity + _Capacity / 2;
if (_Capacity < size() + _Count)
_Capacity = size() + _Count;
pointer _Newvec = this->_Alval.allocate(_Capacity);
pointer _Ptr = _Newvec;
_TRY_BEGIN
_Ptr = _Umove(_Myfirst, _VEC_ITER_BASE(_Where),
_Newvec);
_Ptr = _Ucopy(_First, _Last, _Ptr);
_Umove(_VEC_ITER_BASE(_Where), _Mylast, _Ptr);
_CATCH_ALL
_Destroy(_Newvec, _Ptr);
this->_Alval.deallocate(_Newvec, _Capacity);
_RERAISE;
_CATCH_END
|
首先会尝试扩容1.5倍,如果扩容1.5倍之后依然无法满足size,就会将容量设置为当前size+新增数据的个数,然后再分配内存。
下面再用一个例子给出IDA分析视角
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| #include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
int main() {
std::vector<int> vec1(10);
std::transform(vec1.begin(), vec1.end(), vec1.begin(), [](int i) { return i * i; });
for (int num : vec1) {
std::cout << num << " ";
}
std::cout << std::endl;
int sum = std::accumulate(vec1.begin(), vec1.end(), 0);
std::cout << "Sum of squares: " << sum << std::endl;
int product = std::accumulate(vec1.begin(), vec1.end(), 1, std::multiplies<int>());
std::cout << "Product of squares: " << product << std::endl;
std::vector<int> vec2(10, 1);
std::transform(vec2.begin(), vec2.end(), vec2.begin(), [](int i) { return i + 1; });
double average = std::accumulate(vec2.begin(), vec2.end(), 0.0) / vec2.size();
std::cout << "Average of transformed vec2: " << average << std::endl;
std::fill(vec1.begin(), vec1.end(), -1);
std::cout << "After filling with -1: ";
for (int num : vec1) {
std::cout << num << " ";
}
std::cout << std::endl;
auto it = std::find(vec2.begin(), vec2.end(), 5);
if (it != vec2.end()) {
std::cout << "Found 5 at position: " << std::distance(vec2.begin(), it) << std::endl;
} else {
std::cout << "5 not found in vec2" << std::endl;
}
vec1.emplace_back(42);
std::cout << "After emplace_back(42), vec1 back: " << vec1.back() << std::endl;
vec2.resize(5);
std::cout << "After resize(5), vec2 size: " << vec2.size() << std::endl;
vec1.reserve(20);
std::cout << "After reserve(20), vec1 capacity: " << vec1.capacity() << std::endl;
vec1.shrink_to_fit();
std::cout << "After shrink_to_fit(), vec1 capacity: " << vec1.capacity() << std::endl;
return 0;
}
|
IDA视角如下

vector需要先初始化一个allocator,然后传入std::vector<int>::vector(vec1, 10LL, v57)用于分配内存空间。

这一段对应着std::transform(vec1.begin(), vec1.end(), vec1.begin(), [](int i) { return i * i; });这行代码,具体实现如下

再往下看

这一段也挺好识别的,因为没有去符号表,c++的各种接口都很明显。

后续部分也基本类似,如果不去掉符号表的话其实IDA的伪代码已经挺好看了。
3.类
以如下代码为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include<stdio.h>
#include<stdlib.h>
class base {
public:
int a;
double b;
base() {
this->a = 1;
this->b = 2.3;
printf("base constructor\n");
}
void func() {
printf("%d %lf\n", a, b);
}
virtual void v_func1() {
printf("base v_func1()\n");
}
virtual void v_func2() {
printf("base v_func2()\n");
}
~base() {
printf("base destructor\n");
}
};
class derived :public base {
public:
derived() {
printf("derived constructor\n");
}
virtual void v_func() {
printf("derived v_func()");
}
~derived() {
printf("derived destructor\n");
}
};
int main(int argc, char** argv) {
base a;
a.func();
a.v_func1();
base* b = (base*)new derived();
b->func();
b->v_func2();
return 0;
}
|
其中有基类,派生类,类中有成员变量,成员函数,虚函数。
直接看到IDA视角
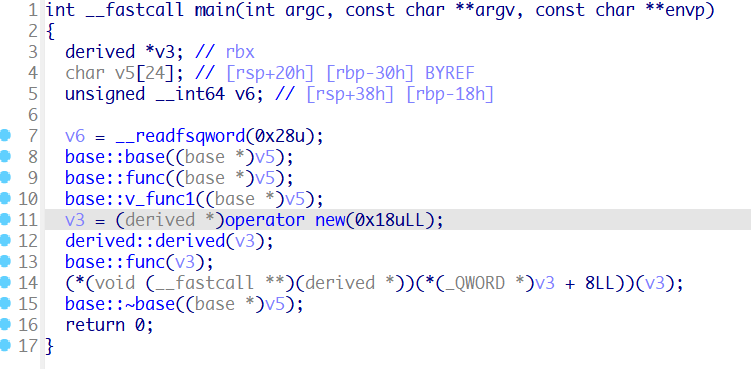
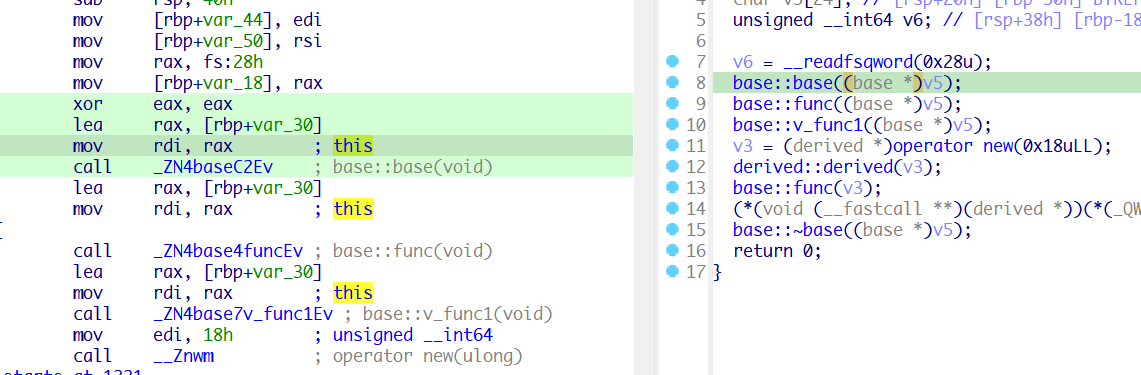
可以看到,base类的每一个函数都传入了this指针,this指针为类函数的第一个参数,通过rdi传参。
看到构造函数
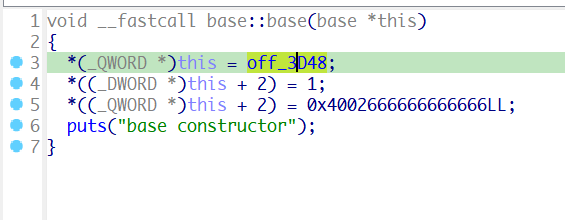
this的首字段并不是成员变量,而是一个地址,这个地址实际上就是虚函数表
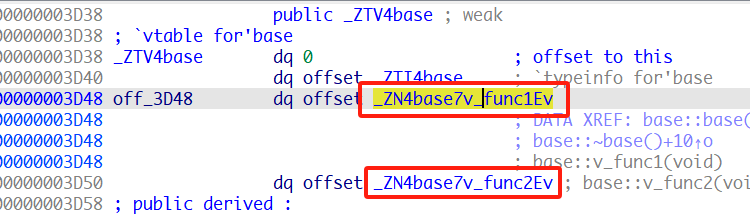
这个地址称为虚表指针,是由编译器在类中添加的隐藏成员。
在虚表地址上方还有一个typeinfo,typeinfo是编译器生成的特殊类型信息,包括对象继承关系、对象本身的描述等。
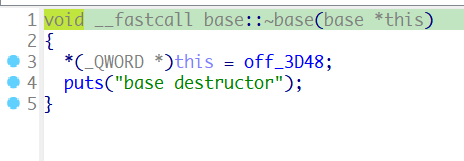
在析构函数中,同样对this的首字段进行了赋值,因为编译器无法预知这个子类以后是否会被其他类继承,如果被继承,原来的子类就成了父类,在执行析构函数时会先执行当前对象的析构函数,然后向祖父类的方向按继承线路逐层调用各类析构函数,当前对象的析构函数开始执行时,其虚表也是当前对象的,所以执行到父类的析构函数时,虚表必须改写为父类的虚表。编译器产生的类实现代码,必须能够适应将来不可预知的对象关系,故在每个对象的析构函数内,要加入自己虚表的代码。

v3是derived类实例的地址
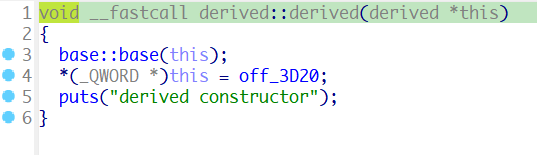
在构造函数中初始化了虚表指针
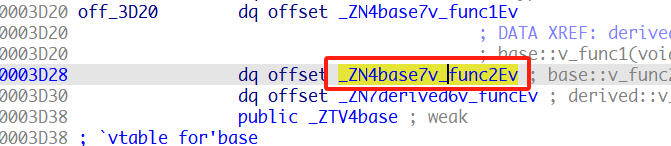
*v3+8就是func2的地址。
再看一下类的继承,derived类的父类是base类,如上图,在derived类的构造函数中,会先执行base类的构造函数,再进行derived类的初始化,derived类的虚表函数中有三个函数指针,前两个都是base类的,第三个是自己的。我们将derived类自己的虚函数注释掉,再看看它的虚表会有什么变化。
1
2
3
4
5
6
7
8
9
10
11
12
13
| class derived :public base {
public:
derived() {
printf("derived constructor\n");
}
~derived() {
printf("derived destructor\n");
}
};
|
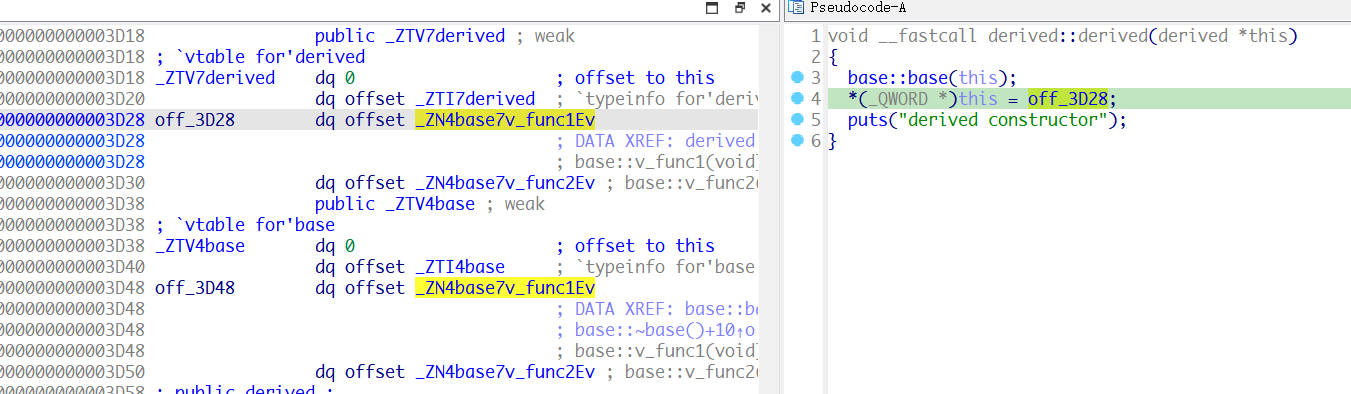
我们看到,即使derived没有自己的虚函数,它自己也有一套独立的虚表,内容和base类的一样。
再看到全局变量类,并且有虚函数的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| #include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iostream>
using namespace std;
class Global
{
public:
Global()
{
printf("Global\n");
}
Global(int n)
{
printf("Global(int n) %d\n", n);
}
Global(const char *s)
{
printf("Global(char *s) %s\n", s);
}
virtual ~Global()
{
printf("~Global()\n");
}
void show()
{
printf("Object Addr: 0x%p", this);
}
};
Global g_global1;
Global g_global2(10);
Global g_global3("hello C++");
int main(int argc, char *argv[])
{
g_global1.show();
g_global2.show();
g_global3.show();
return 0;
}
|
虚表应该在类的构造函数中初始化,但是在本例中,类为全局变量,不在main函数中声明,那么此时虚表应该在何时初始化呢?
在执行main函数之前会调用init_array中的函数,全局类的初始化函数就放在init_array中,称之为构造代理函数


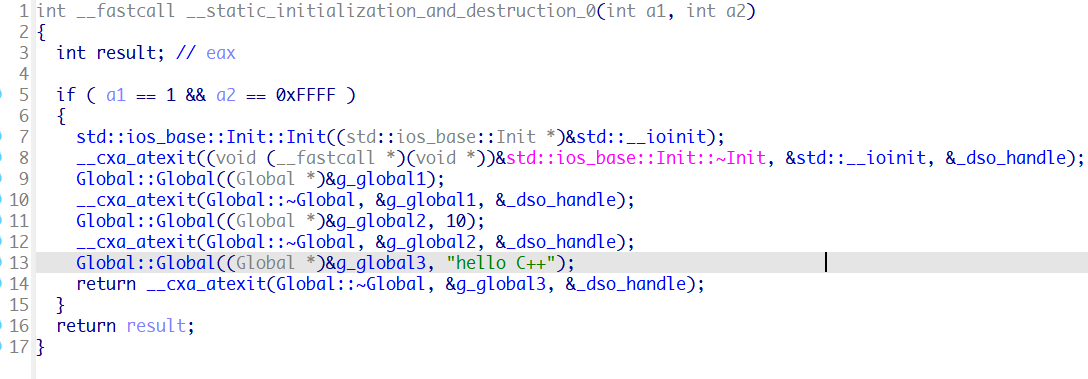
最终在__static_initialization_and_destruction_0中进行初始化,__cxa_atexit函数将在main函数结束时调用,用于析构全局类。
多重继承
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| #include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iostream>
using namespace std;
class Sofa
{
public:
Sofa()
{
color = 2;
}
virtual ~Sofa()
{
printf("virtual ~Sofa()\n");
}
virtual int getColor()
{
return color;
}
virtual int sitDown()
{
return printf("Sit down and rest your legs\r\n");
}
protected:
int color;
};
class Bed
{
public:
Bed()
{
length = 4;
width = 5;
}
virtual ~Bed()
{
printf("virtual ~Bed()\n");
}
virtual int getArea()
{
return length * width;
}
virtual int sleep()
{
return printf("go to sleep\r\n");
}
protected:
int length;
int width;
};
class SofaBed : public Sofa, public Bed
{
public:
SofaBed()
{
height = 6;
}
virtual ~SofaBed()
{
printf("virtual ~SofaBed()\n");
}
virtual int sitDown()
{
return printf("Sit down on the sofa bed\r\n");
}
virtual int sleep()
{
return printf("go to sleep on the sofa bed\r\n");
}
virtual int getHeight()
{
return height;
}
protected:
int height;
};
int main(int argc, char *argv[])
{
SofaBed sofabed;
return 0;
}
|
定义了一个sofa类和一个bed类,sofabed类继承自这两个类。
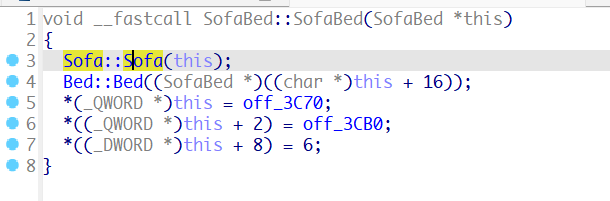
sofabed类的构造函数会依次执行sofa和bed的构造函数
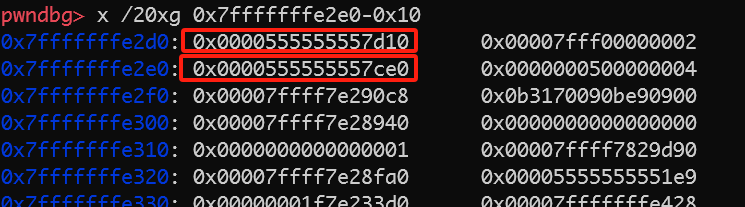
这两个分别是sofa和bed的虚表指针,当sofa和bed构造完成之后就会执行sofabed的构造函数
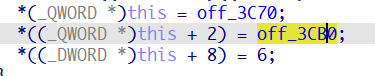
sofabed会将两个虚表指针修改为自身的虚表指针。可见,在多重继承中,子类虚表指针的个数取决于继承的父类的个数,有几个父类便会出现几个虚表指针。
再看有纯虚函数的类,也就是抽象类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| #include <stdio.h>
class AbstractBase
{
public:
AbstractBase()
{
printf("AbstractBase()");
}
virtual void show() = 0;
};
class VirtualChild : public AbstractBase
{
public:
virtual void show()
{
printf("抽象类分析\n");
}
};
int main(int argc, char *argv[])
{
VirtualChild obj;
obj.show();
return 0;
}
|

抽象类也有虚表,只不过虚表函数什么都没干。
虚继承

B继承于A,C继承于A,D继承于B和C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
| #include <stdio.h>
class Furniture
{
public:
Furniture()
{
printf("Furniture::Furniture()\n");
price = 0;
}
virtual ~Furniture()
{
printf("Furniture::~Furniture()\n");
}
virtual int getPrice()
{
printf("Furniture::getPrice()\n");
return price;
};
protected:
int price;
};
class Sofa : virtual public Furniture
{
public:
Sofa()
{
printf("Sofa::Sofa()\n");
price = 1;
color = 2;
}
virtual ~Sofa()
{
printf("Sofa::~Sofa()\n");
}
virtual int getColor()
{
printf("Sofa::getColor()\n");
return color;
}
virtual int sitDown()
{
return printf("Sofa::sitDown()\n");
}
protected:
int color;
};
class Bed : virtual public Furniture
{
public:
Bed()
{
printf("Bed::Bed()\n");
price = 3;
length = 4;
width = 5;
}
virtual ~Bed()
{
printf("Bed::~Bed()\n");
}
virtual int getArea()
{
printf("Bed::getArea()\n");
return length * width;
}
virtual int sleep()
{
return printf("Bed::sleep()\n");
}
protected:
int length;
int width;
};
class SofaBed : public Sofa, public Bed
{
public:
SofaBed()
{
printf("SofaBed::SofaBed()\n");
height = 6;
}
virtual ~SofaBed()
{
printf("SofaBed::~SofaBed()\n");
}
virtual int sitDown()
{
return printf("SofaBed::sitDown()\n");
}
virtual int sleep()
{
return printf("SofaBed::sleep()\n");
}
virtual int getHeight()
{
printf("SofaBed::getHeight()\n");
return height;
}
protected:
int height;
};
int main(int argc, char *argv[])
{
SofaBed sofabed;
Furniture *p1 = &sofabed;
Sofa *p2 = &sofabed;
Bed *p3 = &sofabed;
printf("%p %p %p\n", p1, p2, p3);
return 0;
}
|
看到sofabed的构造函数
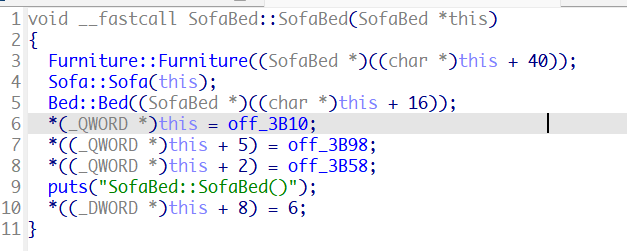
furniture传入的参数是*this + 40,说明furniture这个基类位于sofabed类的最底部,sofa类位于最上方,bed类位于sofa类下方。
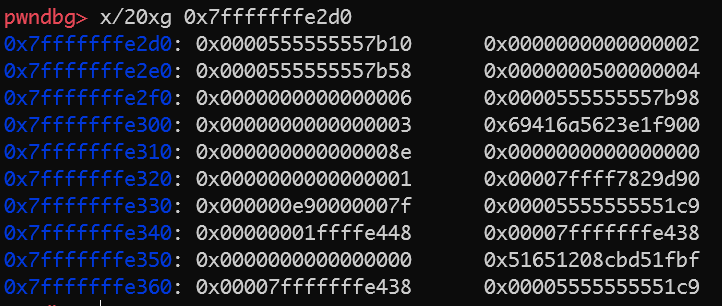
开头0x10字节为sofa类,紧跟着的0x18字节为bed类,后面的6是sofabed类的height,之后的就是furniture类了。
虚基类继承只会初始化一次虚基类。
参考连接:
1.c++ 机制逆向分析 – wsxk’s blog – 小菜鸡
2.C++逆向学习(四) 类 - 先知社区 (aliyun.com)